
O čem bude řeč
Na úvod je potřeba trocha teorie, neboť nepředpokládám, že většina čtenářů má podrobnější biologické znalosti. Zajímám se o genetickou příbuznost mezi rostlinnými populacemi na úrovni krajiny. Z toho pak můžeme usuzovat na historii šíření a logiku dnešního rozšíření. Je to trochu podobná otázka, jako kdybychom se ptali, jaká je genetická příbuznost mezi obyvateli Prahy a Brna a jestli se víc projevuje D1 jako migrační koridor (vyšší příbuznost) anebo Vysočina jako migrační bariéra (nižší příbuznost).
Já ale nepracuji s lidmi, ale s vodními rostlinami. To je ale jedno; parafrází klasika - jsme stejného genetického základu, ty i já. Na úrovni DNA jsou si živáčkové podobnější, než se zdá. Poznání mechanismů a logiky šíření a rozšíření rostlin v krajině má i veliký praktický význam. Od pochopení obecných mechanizmů šíření rostlin (pak víme, kam povedou naše – i nechtěné – zásahy do životního prostředí) přes ochranu vzácných druhů po potlačování těch invazních (mnohdy způsobujících velké hospodářské škody).
Začínáme pracovat
Dnešní biolog, ať už pracuje sebevíce v terénu, se bez počítače prostě neobejde. Mezi základní vybavení tak patří pořádný prohlížeč a kancelářský balík. Ani jedno z toho není nutné představovat. Jen upozorním, že oproti běžné kancelářské práci mají mnohem větší význam tabulkový editor (zapisování dat pro budoucí výpočty) a práce s databázemi (když tabulky nestačí...). Důležitá je také práce s literaturou. Ve vědecké práci totiž musí veškerá tvrzení ve vašich článcích být vaše vlastní výsledky, anebo musíte citovat původního autora, od kterého to víte (a který to doloží svým vlastním výzkumem). Buď můžete použít vestavěnou funkci OpenOffice.org anebo LaTeX, a zvláště pak jeho bibliografické rozšíření BibTeX. Já s oblibou používám Kile a KBibTeX. Asi nejpoužívanější databáze vědeckých článků i vědecky zaměřený Google Scholar umí exportovat záznamy do BibTeXu (*.bib). Z KBibTeXu lze exportovat do HTML, RTF i PDF. Program je velice pohodlný a obsahuje integrované vyhledávání ve vědeckých databázích.
 Úprava článku v KBibTeXu je velice jednoduchá
Úprava článku v KBibTeXu je velice jednoduchá
Jelikož pracuji s rozšířením rostlin v prostoru, velmi důležitá je práce s mapami. Můžete pak zobrazit lokality výskytu vámi studovaného druhu a počítat vzdálenosti mezi populacemi, jak se příbuznost (genetická podobnost) mění se vzdáleností apod. Samozřejmostí je využití GPS. Většinou je možné exportovat data z GPS přímo do tabulkového editoru, ale zdaleka ne vždy je linuxový ovladač plně funkční a krom toho je mnohdy stejně pohodlnější psát si v terénu poznámky na papír a do počítače to zanést až v klidu doma. Odpadne tím spousta problémů s baterkami a získávání dat z přístroje upadlého do řeky.
Pro profesionální zpracování geografických dat je pod Linuxem asi nejpopulárnější geografický informační systém Quantum GIS a GRASS GIS. Oba jsou špičkové a zdarma. Globálně je ale asi nejpopulárnější neuvěřitelně předražený ArcGIS od ESRI. Jsou tu prostě věci mezi nebem a zemí, kterým asi nikdy neporozumím...
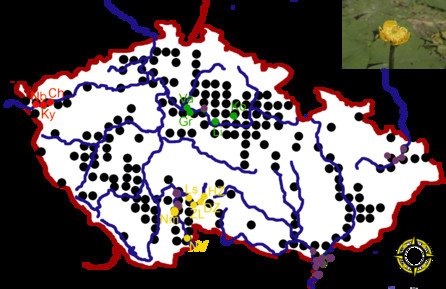 Mapka rozšíření stulíku žlutého
Mapka rozšíření stulíku žlutého
Moje vlastní data pro GIS zatím nejsou v publikovatelné podobě (=nejsou hezká na pohled), tak přikládám jen mapku rozšíření stulíku žlutého, na kterém provádím své výzkumy.
Po teoretické přípravě přichází fáze terénní práce: objet všechny lokality výskytu vámi studovaného druhu, odebrání vzorků, zanesení do mapy a sepsání záznamů. Následují laboratorní analýzy.
V laboratoři
Pracuji s DNA. Existují dvě základní techniky získávání informací z DNA. Buď ji "čteme" písmeno po písmenu, anebo ji na určených místech "štípeme" (fragmentujeme), čímž získáme různě dlouhé proužky DNA. Na gelu pak výsledný obrázek připomíná čárový kód. Těžší úseky se pohybují pomalu, malé rychle, tak se nám rozvrství. Každý jedinec má proužky trochu jiné, můžeme je tak přesně odlišit. Délka jednotlivých úseků DNA je pak podobný znak jako třeba délka listu. Když takových znaků máme víc, můžeme přesně určit příbuznost mezi jedinci a identifikovat jednotlivé jedince. Protože čtení z gelu není příliš pohodlné, používá se speciální přístroj, tzv. sekvenátor.
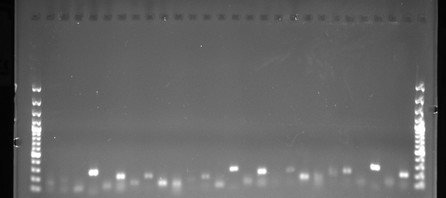 Různě dlouhé úseky DNA na gelu odlišují různé jedince
Různě dlouhé úseky DNA na gelu odlišují různé jedince
Sekvenátory jsou velice drahé (řádově miliony kč), běžně k nim je hardwarový klíč a předinstalovaný počítač s nějakou verzí Windows a speciálními ovladači. Pokud se výrobce nerozhodne postavit obslužný počítač na Linuxu, není tu pro něj místo. Vyprodukovaná data už na na linuxovém stroji zpracovat lze. Pro fragmentační data obecně existuje mnohem méně softwaru než pro data sekvenační (pořadí písmen v DNA, třeba ATGCTTAACTAAG).
Jedním z nejlepších je GeneMarker, jehož prakticky plně funkční demoverzi lze zdarma stáhnout. Program je sice jen pod Windows, ale po doinstalování MSXML4 pomocí Winetricks (v openSUSE součást balíku wine) ochotně běží pod Wine. Program slouží k pohodlnému čtení dat, která si pak zapíšeme do OpenOffice.org Calc.
 GeneMarker běžící pod Wine
GeneMarker běžící pod Wine
Jednotlivé vrcholy odpovídají proužkům na gelu výše a slouží k jednoznačné identifikaci jedinců.
U počítače
Nyní již máme všechna data zapsána do úhledné tabulky a začíná ta hlavní softwarová práce. Dosud jsme pracovali z nemalé části rukama, nyní přišla řada na počítač. Při práci s daty existují, alespoň v biologii, dvě trochu odlišné cesty. Spousta biologů, co umí alespoň trochu programovat, si napíše nějaký malý prográmek určený speciálně pro jejich úlohu. Běžně píšou v Javě a poskytují binárky pro Windows, Linux i Mac. Software je sice zdarma, ale zdrojové kódy k němu nebývají. Když ale autorovi napíšete, obvykle reaguje velice rychle. Nutno také poznamenat, že biologové nebývají nejlepšími programátory, a tak výsledek bývá funkční, ale z pohledu informatika ne nejčistší. Je to komplikovaný problém. Skvělý informatik málokdy rozumí tomu, co má pro biologa naprogramovat a chudák biolog má na práci i jiné věci než pilovat svůj kód. Takto ve výsledku můžete mít spoustu prográmků, z nichž každý dělá jen jednu věc, ale zato pořádně.
Jinou možností je použít nějaký z velkých balíků. Pro velkou většinu statistiky je asi nejpopulárnější balík R, pro matematické modely pak Octave. Častý je i Scilab.
Já prozatím kombinuji obě cesty. Pro základní zpracování "surových" dat používám program MSA, který má z pohledu uživatele Linuxu přímo otřesné ovládání. Za to ale spočítá všechny potřebné genetické koeficienty a připraví data k dalšímu použití.
 MSA počítá skvěle, ale jeho ovládání je poněkud svérázné
MSA počítá skvěle, ale jeho ovládání je poněkud svérázné
Pro výpočet parametrů populační genetiky je skvělým pomocníkem Arlequin. Tyto údaje nám poodhalí, kolik procent genetické variability se skrývá mezi jedinci v rámci jedné populace a kolik mezi populacemi na úrovni krajiny. Dozvíme se tak např., jak moc dochází k výměně jedinců mezi populacemi a jak moc je pro daný druh důležitá migrace z místa na místo. Arlequin je napsán v Javě a pro Linux je k dispozici soubor JAR. Jeho spuštění je pro mě vždy z nějakého záhadného důvodu dosti obtížné, a tak si raději pod Wine pouštím verzi pro Windows.
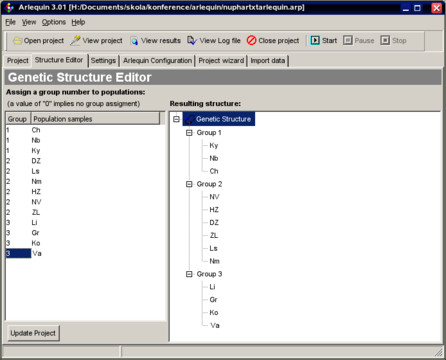 Nastavení struktury vzorků do populací pro další výpočty
Nastavení struktury vzorků do populací pro další výpočty
Oba zmíněné programy lze nahradit balíkem R (např. balíky adegenet, agce, BiodiversityR), ale bez další práce to není náhrada kompletní. A je asi uživatelsky méně pohodlná. Pro další výpočty můžeme opět využít balík R. Najdete jej např. v repozitářích Debianu, Ubuntu nebo v repozitáři projektu Education pro openSUSE. Nejvíce doplňkových modulů je v repozitáři pro R Marka Stopky. Já používám mj. balíky adegenet, BiodiversityR, cluster, FactoMineR, fpc nebo vegan.
 Nastavení výpočtů v Arlequinu
Nastavení výpočtů v Arlequinu
Pro ty, kdo se nikdy nesžili s příkazovou řádkou R, existují pod Linuxem minimálně dvě zajímavé možnosti. První je R4Calc, doplněk do OpenOffice.org, který do Calcu přidá nové menu; to umožňuje spouštět příkazy R přímo z Calcu. Velice zajímavým projektem je Rkward. Poskytuje kompletní grafické rozhraní pro práci s R. Pohodlný tabulkový editor pro úpravy dat, snadné operace s doplňkovými moduly, zvýraznění syntaxe během psaní, debugger, log apod. Oba projekty procházejí bouřlivým vývojem a jsou stále lepší a lepší.
 R4Calc, spouštění R z OpenOffice.org Calc
R4Calc, spouštění R z OpenOffice.org Calc
 Rkward, pohodlné GUI pro R
Rkward, pohodlné GUI pro R
Software pro biology není v Linuxu problém
Vědecký software nebývá proslaven krásou grafických výstupů. Mnohdy je vhodné data pro grafy vzít a nakreslit je např. pomocí OpenOffice.org Calc. Neocenitelnými pomocníky jsou také známé grafické editory GIMP a Inkscape. Na konci opět přichází ke slovu kancelářské aplikace anebo LaTeX.
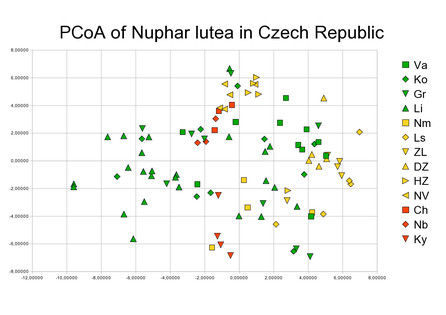 Prostorové znázornění příbuznosti populací
Prostorové znázornění příbuznosti populací
Vypočítané v R a nakreslené v OpenOffice.org Calc. Jednotlivé barvy jsou geografické oblasti a symboly populace. Promíšenost skupin naznačuje, že mezi populacemi dochází k čilé výměně genetického materiálu (křížení).
Snažil jsem se vám ukázat, jak vypadá jedna z mnoha možností nasazení Linuxu ve vědě. Možnosti jsou prakticky neomezené, stačí jen chvilku pátrat po vhodném softwaru. Doufám, že jsem vás přesvědčil, že Linux je platný i na tomto poli lidského konání a také doufám, že jste se nezalekli přemíry biologie na tomto počítačovém serveru. Přátelé pracují se sekvencemi DNA a obrovskými on-line databázemi molekulárních dat, svou laboratoř opouštějí jen zřídka a neradi mají v tomto ohledu situaci jednodušší. Některý špičkový speciální software je k dispozici jen pro Linux. Živou přírodu sice studují povětšinou pomocí počítače, ale tučňák je stále s nimi. :-)
Pokud vás téma zaujalo a nebojíte se angličtiny ani odborné biologie, můžete se podívat (PDF).













