
Trénování neuronových sítí je velká zábava! Ale je tu jeden menší problém – potřebuješ dostatek výpočetní síly. Jistě, můžeš oprášit svůj starý notebook, po několika neúspěšných pokusech nainstalovat TensorFlow a poté pár let počkat, aby se vůbec něco naučil... a staneš se hrdinou!
No, realita je ve skutečnosti trochu jiná. Pokud nechceš, aby ses čekáním unudil, potřebuješ získat nejnovější GPU akcelerátory, ideálně rovnou celý cluster. Když se ti to podaří a před tebou je tvoje nejvypiplanější neuronová síť, potřebuješ už pouze jediné – nasadit ji do skutečného světa. Můžeš zůstat u své GPU farmy či cloudu, který jsi použil na trénování. Ale co když si zákazník přeje on-premise řešení (žádný cloud) nebo by latence, resp. objem dat, vzdálené výpočty neumožnily?
Mohl by se tam vybudovat menší GPU cluster? Nejspíš ano, ale to by bylo příliš drahé řešení. Co jeden počítač s GPU? To vypadá proveditelně, ale ne v případě, že potřebuješ více výpočetních jednotek. V takovém případě přijdou na řadu edge zařízení pro AI. Když nejdou data k umělé inteligencí, musí inteligence za daty.
Co je edge zařízení pro AI?
Edge, v kontextu technologií, odkazuje zejména na výpočetní infrastrukturu, která je umístěna blízko zdroji dat. Přesunuje centrum výpočtu z cloudu nebo centralizovaných uzlů do těch nejkrajnějších částí sítě. Edge zařízení pak odkazuje na konkrétní fyzický hardware, který je součástí takové výpočetní infrastruktury.
Můžeme u edge zařízení pro AI dosáhnout dostatečného výkonu? A to i pro scénáře, které běží (téměř) v reálném čase? Měl jsem za to, že „ano, mělo by to být možné“, ale nenašel jsem žádné dostatečné porovnání, které by mě uspokojilo. A proto jsem zde – abych se podělil o své výsledky.
V další části nejprve stručně vysvětlím použitou hardwarovou konfiguraci a sady nástrojů, které používám. Dále se zaměřím na benchmarking a průběh jednotlivých testů. Po porovnání a diskusi o výsledcích uzavírám tento článek krátkým přehledem existujících řešení a zamyšlením nad možnými budoucími kroky.
Intel Movidius Neural Compute Stick
Minulý rok jsem se dostal k jednomu kusu Intel Movidius Neural Compute Stick (NCS). Vím, že je to už více než dva roky, kdy byl vydán, ale pokud obstojí v testech, pak musí být i novější hardware dostatečný.

Intel popisuje Movidius NCS jako:
Toto drobné, bezhlučné zařízení pro hluboké učení vám umožní AI programování pro edge.
Je to skutečně drobné zařízení, stačí si představit svou USB flashku, nepřesahuje 8 cm. Klíčem k úspěchu je specializovaná výpočetní jednotka Vision Processing Unit (VPU). Nese název Intel Movidius Myriad VPU 2, což je druhá generace VPU společnosti Movidius. Obsahuje 12 programovatelných SHAVE jader (vektorové procesory optimalizované pro strojové vidění pro zrychlení neuronových sítí spouštěním jejich částí paralelně), dva 32-bitové procesory (RISC), 4Gb LPDDR3 DRAM a další grafické a vizuální akcelerátory.
Zde jsou detaily: ProductBrief.pdf
Pro první verzi Movidius NCS potřebujete operační systém založený na Ubuntu s USB 2.0 a alespoň 1 GB paměti RAM.
Benchmark setup
Benchmarky jsou prováděny výhradně na dvou hardwarových konfiguracích uvedených níže. Pro zjednodušení se budu odkazovat na vybranou konfiguraci jako Laptop a Raspberry Pi (RPi). Důležitou součástí jsou samozřejmě i použité nástroje a samotná metodika, které popisuji níže pod tabulkou konfigurace.
Hardwarové konfigurace
|
Laptop |
Raspberry Pi (RPi) |
|
Dell G3 15 Gaming |
RPi 3 B+ |
|
Ubuntu 16.04.5 LTS |
Raspbian GNU/Linux 9 (stretch) |
|
Intel(R) Core(TM) i5-7300HQ CPU @ 2.50GHz |
1.4GHz 64-bit quad-core ARM Cortex-A53 |
|
NVIDIA GeForce GTX 1050 4GB |
— |
|
RAM 8GB DDR4 |
1GB |
Nástroje
OpenVINO
Pro všechny testy s Movidius používám sadu nástrojů OpenVINO. Pro první verzi Intel NCS je k dispozici také samotné SDK, které ale není kompatibilní s dalšími verzemi tohoto USB akcelerátoru, takže jsem se rozhodl používat OpenVINO, jak Intel doporučuje. Výhoda je v případném rozšíření benchmarků pro další verze tohoto USB akcelerátoru bez nutnosti přechodu na jinou sadu nástrojů. Pro stručný přehled je možné tento nástroj popsat následovně (ze stránek společnosti Intel):
OpenVINO™ toolkit, zkratka pro „Open Visual Inference a Neural Network Optimization toolkit“ (sada nástrojů pro použití a optimalizaci neuronových sítí na vizuálních datech), poskytuje vývojářům zlepšený výkon neuronových sítí na rozličných procesorech Intel® a pomáhá jim dále otevřít dveře k cenově výhodným aplikacím v reálném čase. Tato sada nástrojů umožňuje aplikaci hlubokého učení a snadné heterogenní výpočty napříč různými platformami Intel® (CPU, Intel® Processor Graphics) - poskytuje implementace napříč cloudovými architekturami až po edge zařízení. Je také k dispozici s další, proprietární podporou pro Intel® FPGA nebo Intel® Movidius ™ Neural Compute Stick.
OpenVINO obsahuje Deep Learning Deployment Toolkit (k nasazení modelů hlubokého učení) a Open Model Zoo (s více než 20 předtrénovanými modely). Více se dozvíte na webových stránkách Deep Learning For Computer Vision.
TensorFlow
S OpenVINO můžeme snadno spouštět modely napříč různými platformami Intelu, ale pokud vím, není možné je používat na jiných platformách (např. NVIDIA GPU). Proto pro ostatní testy používám TensorFlow (TF) framework vyvinutý společností Google. Související testy jsou označeny příznakem TF (CPU TF nebo GPU TF). Pokud jste teprve začátečníci, doporučuju věnovat svůj čas jednoduchému úvodu do TF nebo si projít vynikající přehled Effective TensorFlow.
Měření
Při jednotlivých měření se snažím být co nejkonzistentnější přesto, že mezi OpenVINO a TF jsou jisté rozdíly. Pro obě sady nástrojů spouštím vždy 10 běhů po 1000 iteracích s průměrováním výstupů, které utvářejí konečný výsledek. Specificky pro TF přeskakuji prvních několik iterací, abych předešel zkreslení výsledků, kdy se TF session zahřívá.
Vybrané benchmarky
Demo aplikace (AlexNet)
Začněme s něčím opravdu jednoduchým a již (téměř) hotovým. Existuje mnoho příkladů, kde můžeme začít.
Pro jednoduchost přeskočím instalaci a kroky kompilace. Až budete hotovi, je jednoduché spustit něco jako toto (přizpůsobte si cesty ke snímku a modelu):
./benchmark_app -i <path_to_image>/inputImage.bmp -m <path_to_model>/alexnet_fp32.xml -d CPU
Jedná se o ukázkovou aplikaci (benchmark app), která je součástí OpenVINO. Na vstupu požaduje cestu k obrázku (-i), který následovně zpracovává vybraným modelem (-m) na cílovém zařízení (-d). Jediným požadavkem je úspěšná kompilace.
Používám jednoduchou síť AlexNet, která je už natrénovaná na ImageNet datasetu. Není třeba nic trénovat.
Abychom mohli model používat, musíme jej převést do tzv. Intermediate Representation (IR), což je ten správný formát pro OpenVINO. Pro převod modelů na IR je k dispozici nástroj pro optimalizaci modelu (více v této příručce). Pro tento benchmark můžeme použít následující příklad:
python mo.py --framework caffe --data_type FP32 --input_shape [1,3,227,227] --input data --mean_values data[104.0,117.0,123.0] --output prob --input_model <alexnet.caffemodel> --input_proto <alexnet.prototxt>
Je třeba zadat přesnost v plovoucí řádové čárce konečného modelu v IR: a) standardní hodnota (32-bit / FP32) nebo b) poloviční přesnost (16-bit / FP16). Nejjednodušší způsob je nastavení správného parametru pro optimalizaci modelu (--data_type). Výchozí hodnota je FP32. Důležité je vědět, jakou přesnost zařízení skutečně podporuje.
Movidius může spouštět pouze modely ve FP16. Na druhou stranu pokus o spuštění stejného 16-bitového modelu na CPU se nepovede. Pro Intel GPU jsou k dispozici oba módy, ale Intel doporučuje preferovat FP16 oproti FP32, protože je obvykle rychlejší. Na typy FP pro integrovanou GPU se odkazuji jako GPU16 a GPU32.
Existuje mnoho dalších parametrů pro optimalizátor modelu v závislosti na modelu a konfiguraci, jak je vidět na příkladu výše. Podrobné vysvětlení naleznete v této příručce.
Benchmark je možné spustit ve dvou režimech (viz rámeček níže) a měřit FPS (počet zpracovaných snímků za sekundu) nebo latenci (v režimu synchronizace). Všechny testy jsou spouštěny s parametrem --nireq rovným 2. To znamená dva (stejné) požadavky pro každou iteraci.
Sync vs. Async
K dispozici jsou dva režimy – Sync nebo Async. První z nich bychom mohli popsat v krocích „získej snímek, zpracuj snímek, zobraz výsledek“, zatímco druhý má vyhrazená vlákna pro detekci (aktuální snímek) a zachycení dalšího snímku.

Z prvních výsledků vidíme, že se Movidius nejeví v nejlepší světle. Průměrný FPS je zhruba kolem 12, což znamená více než 10krát pomalejší než Intel GPU se stejnou přesností FP (16 bitů) a stále zhruba 5krát pomalejší než CPU. V absolutních číslech je průměrná latence pro Movidius zhruba 81 ms. Pravděpodobně jste si všimli podobnosti mezi výsledky obou módů s výjimkou CPU. To můžeme vysvětlit schopností využití různých jader, což přináší lepší FPS. Nechtěl jsem se primárně zaměřit na CPU výkon, ale bylo by zajímavé použít různá nastavení pro --nireq a ladit --nthreads, abychom zjistili, čeho může asynchronní režim na CPU dosáhnout.
Porovnání s Raspberry
Protože mi jde zejména o edge, pokusil jsem se spustit AlexNet na RPi. Používám stejné nástroje, tedy TF, přestože jeho instalace na RPi není vždy jednoduchá. Jaké jsou výsledky?
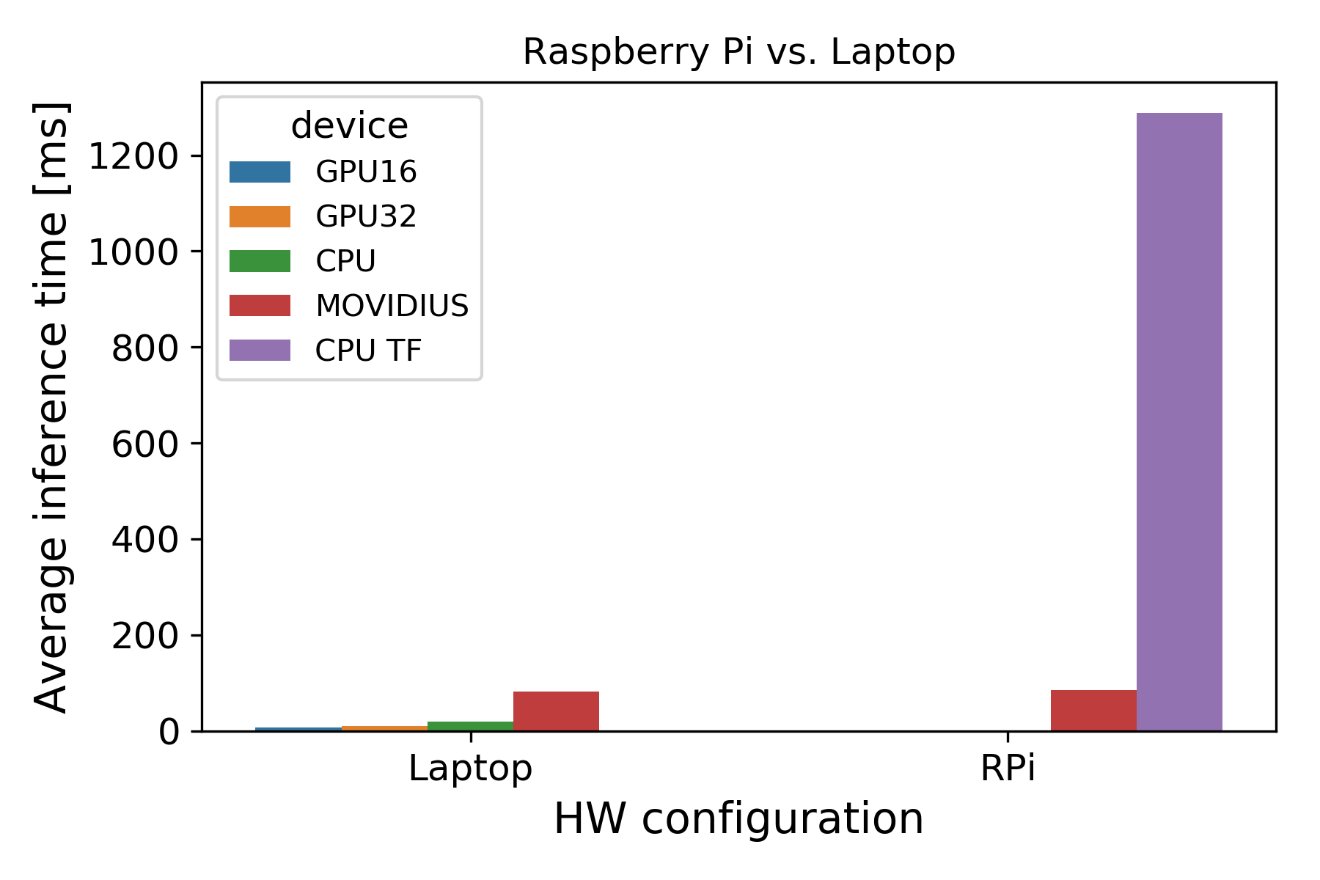
Jak vidíme, Movidius ve srovnání s RPi předvádí obstojné výsledky. Samotné TF bychom mohli pravděpodobně ještě zlepšit nebo použít optimalizovanou verzi OpenCV, abychom dosáhli lepšího „non-Movidius“ času. V mém případě Movidius NCS vykazuje výrazné zlepšení – téměř 15krát nižší latence nám říká, jak jednoduché a efektivní může být použití neuronových sítí pro edge.
YOLOv3 Benchmark
AlexNet není špatný, ale zkusme něco většího. Zejména pro vizuální úlohy, jako je například segmentace obrazu, potřebujete hlubší modely, jako je Mask R-CNN nebo Faster R-CNN. Jenže tady nám situace moc nepřeje:
Faster R-CNN a Mask R-CNN jsou podporovány pouze na CPU s velikostí batche 1 (pozn. red.: tato informace vychází z poznámek k vydaným verzím za loňský rok, které je možné nalézt zde: https://software.intel.com/en-us/articles/OpenVINO-RelNotes-2018, během psaní tohoto článku vyšla první aktualizovaná verze roku 2019, kde to s podporou těchto topologií vypadá o něco lépe).
Jaké zklamání! Doufám, že je budu moct jednou vyzkoušet i na některém dalším USB akcelerátoru od Intelu. Dnes si musíme vybrat něco jiného. Nakonec jsem si vybral síť YOLOv3. Není úplně nejhlubší, ale kompletní v3 je srovnatelná s nejmodernějšími modely v oblasti detekce objektů. Jelikož jsem měl zkušenost s vlastními modely YOLO, vypadalo to jako dobrá volba.
Nebylo to však tak snadné. Pokud chcete použít vlastní natrénovanou neuronovou síť založenou na YOLO, musíte projít několika kroky optimalizátoru modelu, abyste získali správný model v IR. Obvykle to není velký problém, ale s modely YOLO je to jiné. Pokud máte model v originálním formátu (Darknet implementace), musíte nejprve převést model do TF .pb formátu a po tomto kroku můžete použít přímo optimalizátor modelu OpenVINO pro získání správného IR formátu. Problém spočívá v tom, že pro konverzi Darknet na TF Intel spoléhá na externí řešení. A pokud použijete trochu jinou konfiguraci, nebude vám to stačit. Musíte upravit kód v doporučovaném repozitáři (jak načíst a převést soubor .weights) a tudíž musíte přesně vědět, co děláte.
Pro YOLO benchmark jsem spustil YOLO verzi SSD showcase, která existuje pouze v režimu Async: https://software.intel.com/en-us/articles/OpenVINO-IE-Samples#object-detection-SSD-showcase
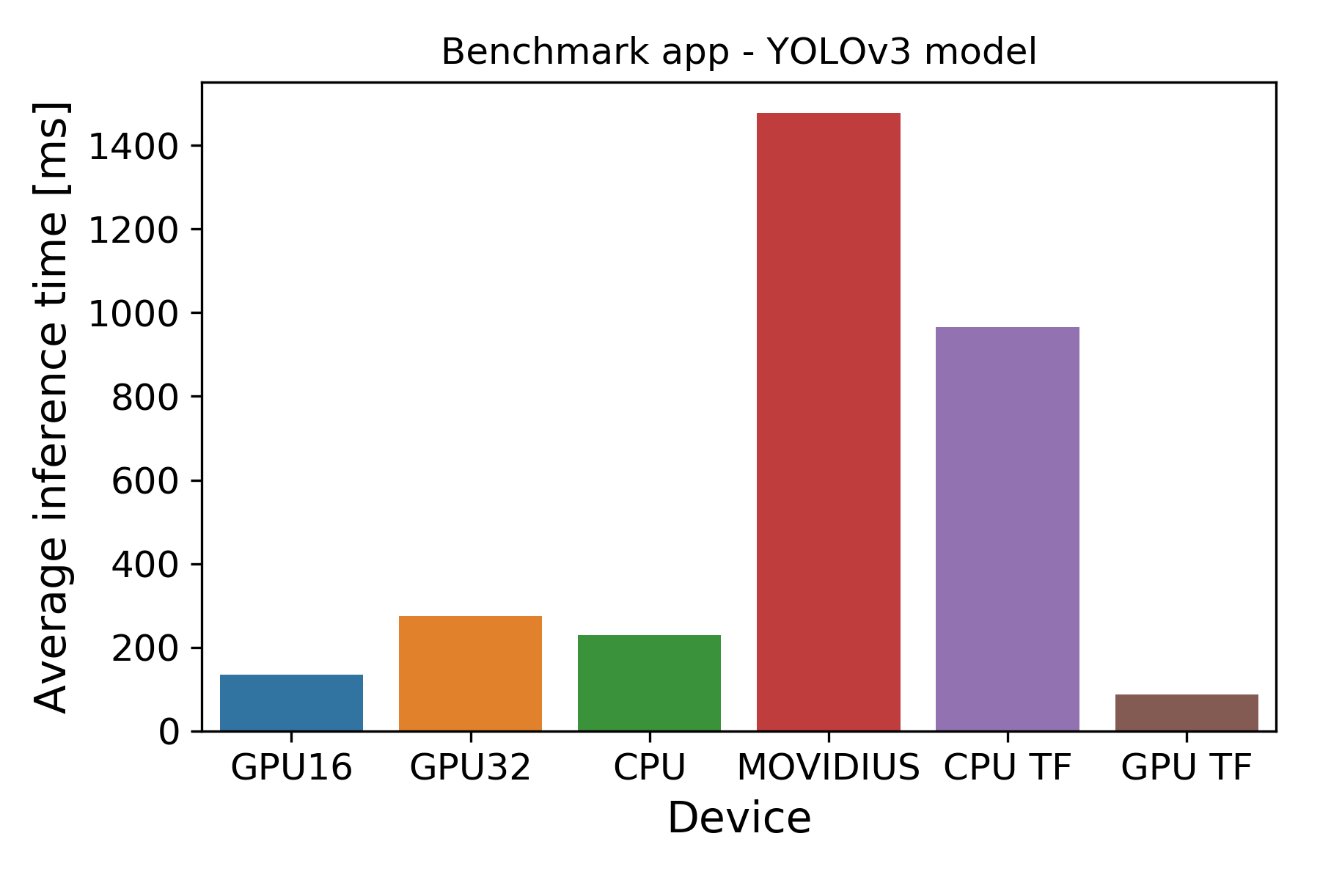
Pozorujeme, že latence Movidius jsou v tomto případě 18krát větší než u modelu AlexNet. Všimněte si velkého rozdílu CPU OpenVINO vůči TF běhu. Moje TF binárka nebyla zkompilovaná pro použití těchto instrukcí CPU: SSE4.1 SSE4.2 AVX AVX2 FM. Obvykle to není problém, protože TF se zaměřuje na GPU. Může to (alespoň částečně) vysvětlit rozdíl mezi různými výsledky CPU založenými na vybraném nástroji. NVIDIA GPU je vítězem YOLO benchmarku, jak jsem očekával, ale rozdíl není dechberoucí. Intel GPU odvádí také velmi dobrou práci – FP32 a FP16 jsou pouze 3krát, respektive 1,5krát pomalejší.
Porovnání Movidius napříč HW
Nakonec bych se ještě podíval na rozdíly ve výsledcích pro Movidius. AlexNet se odkazuje na první benchmark, Custom model je vlastní SSD model, který nebyl zahrnut do benchmarku.
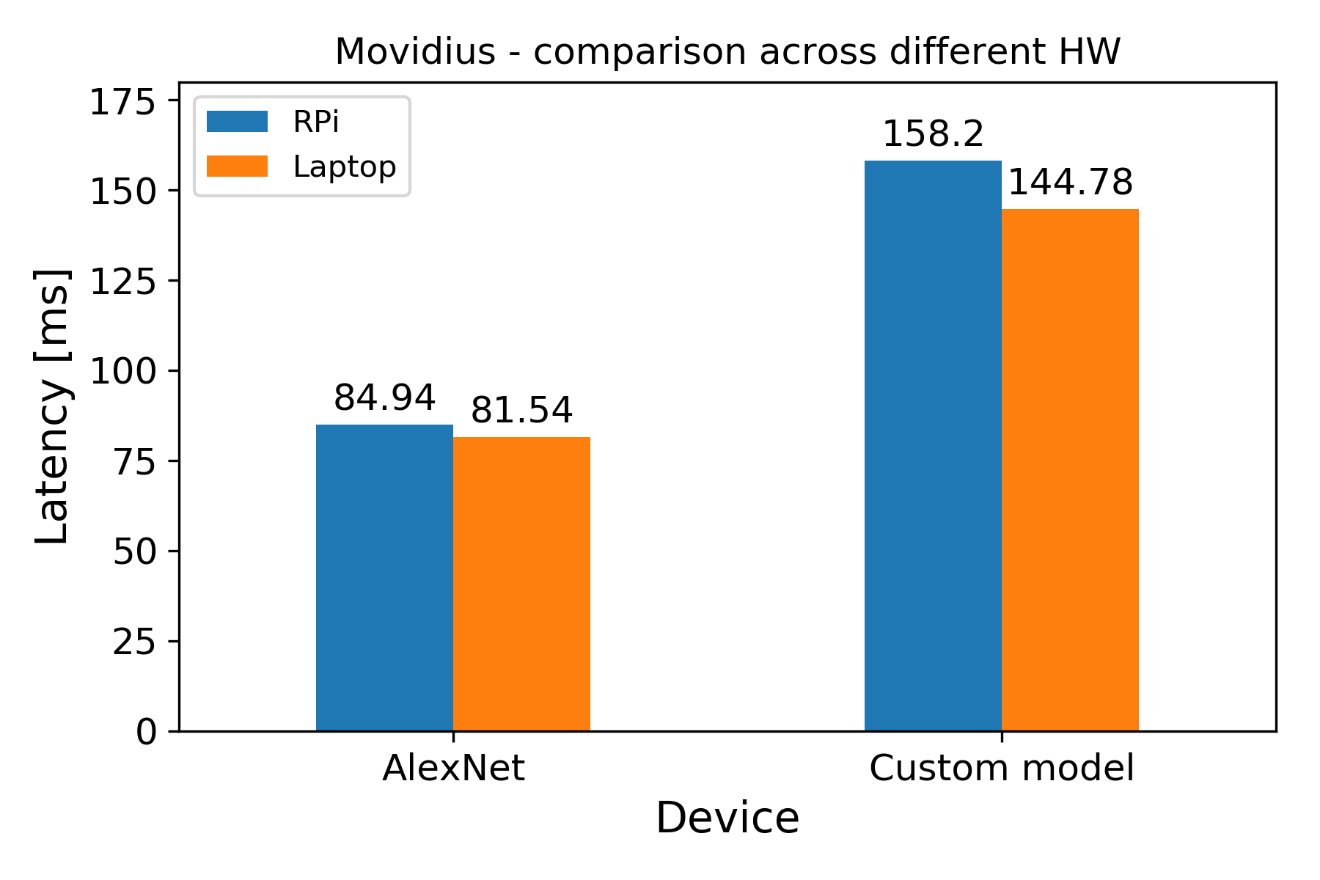
Z grafu je zřejmé, že existují rozdíly ve výsledcích v závislosti na vybraném hardwaru. Jedná se o úplně stejný model, stejnou verzi OpenVINO, stejný Movidius. Není to kritický rozdíl a nemáme dostatek testů pro to, abychom z toho vyvozovali velké závěry, ale stojí to vzít na vědomí a poukázat na to, že USB komunikace přináší určitou režii.
Porovnání v číslech
Podívejme se také na porovnání zrychlení v absolutních číslech. První tabulka je shrnutím pro Intel zařízení, kde všechny byly spouštěny v nástroji OpenVINO, jak jsme již viděli v benchmarcích.
|
|
GPU16 / GPU32 |
GPU16 / CPU |
CPU / GPU32 |
CPU / MOVIDIUS |
|
AlexNet |
1.37 |
2.51 |
0.55 |
4.19 |
|
YOLOv3 |
2.04 |
1.70 |
1.20 |
6.43 |
|
Average speedup |
1.71 |
2.11 |
0.87 |
5.31 |
První sloupec (GPU16 / GPU32) není přesně o různých zařízeních (je to stejná Intel GPU), ale odkazuje na FP modelu. Není divu, že modely s poloviční přesností předčí 32bitové modely, ale neměli bychom zapomínat na možné snížení přesnosti v případě FP16.
Ostatní čísla kvantifikují zrychlení CPU. Je srovnatelný s procesorem Intel GPU s 32bitovým modelem a dosahuje (přibližně, máme pouze dva testy) v průměru 5.3x zrychlení oproti Movidius.
Když se zaměříme na YOLO benchmark v tabulce níže, první, co vidíme, je již zmíněný rozdíl mezi OpenVINO a TF běžící na stejném čipu. NVIDIA GPU překonává CPU, ale není to nic ohromujícího. Očekával bych výraznější rozdíl. Poslední číslo ukazuje, že Movidius je stále daleko od výkonu GPU, ale pokud vezmeme v úvahu, že ho můžeme spustit na RPi s minimálními náklady a spotřebou energie, není to výsledek k zahození.
|
|
YOLOv3 |
|
CPU (OpenVINO) / CPU TF |
4.20 |
|
GPU / CPU (OpenVINO) |
2.63 |
|
GPU / MOVIDIUS |
16.93 |
Shrnutí a diskuze
Zpočátku jsem byl trochu zklamaný. Doufal jsem, že s Movidius dosáhnu porovnatelného výkonu s CPU notebooku. Bohužel to tak není, protože latence jsou 4 až 7krát větší.
Na druhé straně nemůžeme Movidius rovnou odepsat, vzhledem k faktu, že můžeme provozovat malé neuronové sítě v rozumném čase. Zvláště v porovnání s Raspberry Pi je to docela příjemné zlepšení. Když se zaměříme na první benchmark (AlexNet), 15násobné zrychlení je už výrazné, navíc vidíme, že je možné dosáhnout zhruba 12 FPS pro RPi s Movidius.
Nicméně, složitější modely jako YOLOv3 nebo Mask R-CNN nevykazovaly přijatelné výsledky nebo je dokonce nebylo možné vůbec spustit. Stále je náročné použít ty nejkomplexnější modely v edge zařízeních, ale existuje mnoho dalších firem, které se snaží tyto kapacitní nebo výkonnostní problémy překonat a přinést lepší a lepší řešení (viz další řešení níže).
Zajímavý je rozdíl mezi výsledky TF a OpenVINO. Na tuto oblast jsem se příliš nezaměřoval, ale rozdíl není zanedbatelný. Zmínil jsem se o tom, že moje TF binárka není optimalizována pro CPU, ale stále to nevysvětluje všechno (bylo by vhodné porovnat ji s TF CPU optimalizovanou instalací). Mám pocit, že Intel ví, že v jeho silách není porazit GPU v trénování sítí, ale dělá vše, co může, aby vynikal v použití již natrénovaných sítích na nových datech (podívej se na tento článek s porovnáním). Když chceme použít sítě v praxi, kde nasazení GPU není možné nebo ekonomické, zdá se mi, že se Intel snaží prohlásit: „S našimi technologiemi poběží vaše sítě dostatečně rychle, dokonce i na CPU!“.
Na závěr bych rád zmínil řetězení těchto USB akcelerátorů. Mám pouze jedno zařízení, proto jsem to nemohl otestovat. Ale pokud jich máte víc, můžete paralelizovat svoje úlohy. Zde najdete 4 NCS verze 2 připojené k jednomu RPi dosahující až 24 FPS s SSD a YOLOv3 sítěmi.
Další řešení
Ještě jsem neměl příležitost otestovat jiná podobná zařízení. Jedním z klíčových hráčů je jistě NVIDIA se svými zařízeními Jetson. Je to trochu dražší (ve srovnání s Movidius), ale také výkonnější (a náročnější na spotřebu).
AAEON přináší zajímavé řešení s rodinou UP AI EDGE. Mají řešení založené na stejné čipové sadě jako testovaný NCS (Movidius Myriad X) včetně dalších jako je Intel Cyclon FPGA.
Google navrhuje velmi výkonné procesory, tzv. Tensor Processing Unit (TPU), které byly speciálně optimalizovány pro hluboké učení. Nemůžete si je koupit, jsou k dispozici pouze pro cloudové výpočty pod platformami Google. Zajímavé ale je, že společnost vydala menší verze těchto čipů s názvem Edge TPU. Nyní je k dostání pod značkou Coral ve dvou verzích: a) jako jedna vývojová deska a b) jako akcelerátor USB podobně jako Movidius NCS.
V neposlední řadě bychom rozhodně neměli zapomenout na společnost Microsoft, která se zaměřuje na edge také. Můžeme u nich nalézt množství IoT komponent (od edge uzlů a IoT hub až po Azure cloud se spoustou služeb), ale nezapomněli ani na AI a edge výpočty a po dlouhé spolupráci se společností Qualcomm chtějí tuto vizi oživit. První řešení naleznete zde.
Co dále
Rád bych otestoval další řešení, abych získal lepší odhad a porovnání stávajících řešení! Již teď je zde Intel NCS 2 s až osminásobným výkonem oproti původní verzi (měřeno počtem zpracovaných obrazů za sekundu pro GoogleLeNet V1 a Tiny YOLO V1). To je docela slibné, pokud si představíme dosažené výsledky s osmi-násobným zlepšením. Doufejme, že budu mít šanci to otestovat v budoucnu (zatím si můžete přečíst tuto recenzi).
Šimon pracuje ve společnosti Faraday Grid Czech, kde působí na pozici datového vědce. V roce 2016 dokončil magisterské studium v oboru znalostní inženýrství na ČVUT v Praze. V poslední době se věnoval zejména hlubokému učení a jeho aplikaci v oblasti rozpoznávání obrazu. Mezi jeho profesní zájmy patří analýza dat, trénování neuronových sítí a jejich použití (nejen) na mini-počítačích jako je Raspberry Pi.











