
Mozilla pracuje na dvou projektech, které se týkají strojového rozpoznávání řeči. Jedním je Deep Speech, což je model pro rozpoznávání včetně implementace (opírá se o vědeckou práci Deep Speech a využívá knihovnu TensorFlow), druhý komunitní sběr řečových dat Common Voice (zatím v angličtině, ale brzy by měly přibýt i další jazyky).
Nyní Mozilla vydává první ucelenou verzi výsledků obou projektů. Kromě modelu rozpoznávače je součástí také skoro 400 tisíc záznamů řečových dat (dohromady cca 500 hodin) od více než 20 tisíc lidí. Pro účely projektu Deep Speech ale slouží i jiné datové sady, například LibriSpeech nebo VoxForge.
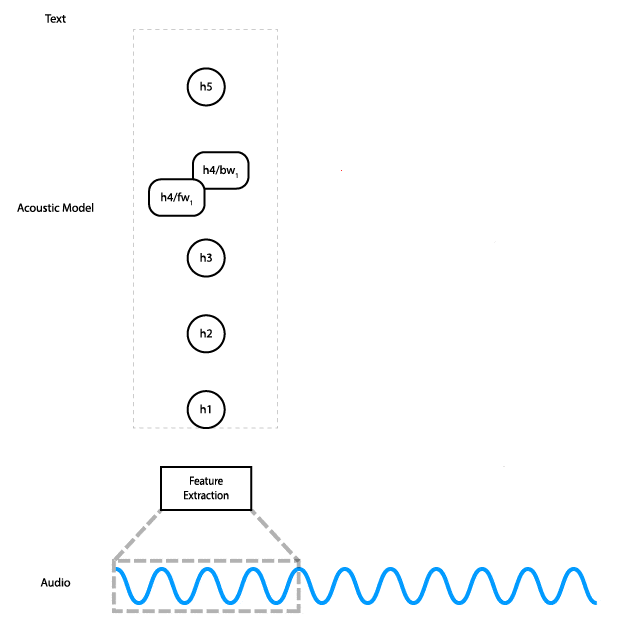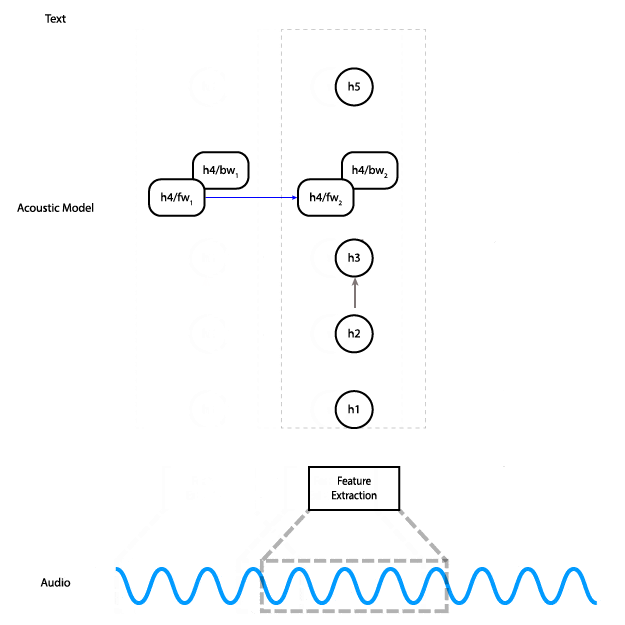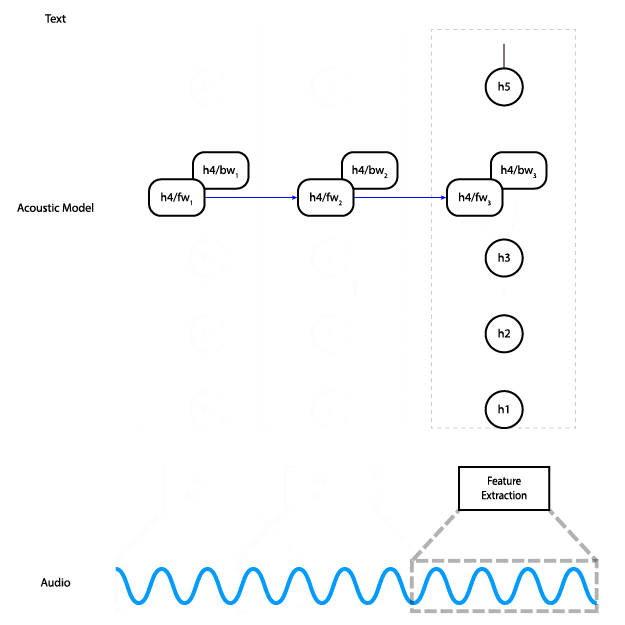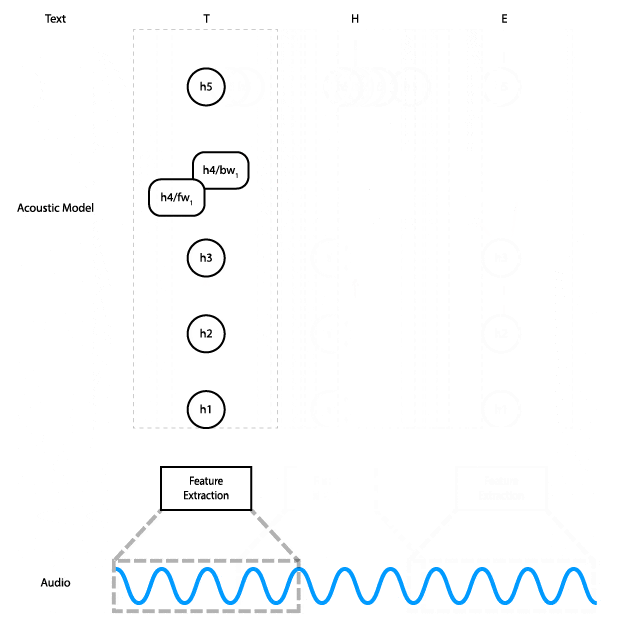
Architektura modelu (Reuben Morais, CC BY-SA 3.0+)












