
IT Security Workshop
IT Security Workshop (ITSW) je odborná konference, která se pravidelně v březnu koná v Praze. Je zaměřena na praktické aspekty IT bezpečnosti (byť se nejedná o skutečný workshop, jak by název napovídal) a účastníci mají možnost se dozvědět například o aktuálních trendech v útocích a ochraně před nimi, o zabezpečení infrastruktury či softwaru apod.
Hlavním mediálním partnerem letošního ročníku ITSW byl náš časopis IT Systems.
 Velký přednáškový sál na konferenci ITSW
Velký přednáškový sál na konferenci ITSW
Letos – stejně jako v minulých letech – se konference konala Konferenčním centru City na Pankráci. Byla koncipována jako jednodenní s kratším programem, bez rozdělení obědem – ten následoval až po skončení konference (do programu byly zařazeny jen krátké přestávky na občerstvení podávané v předsálí).
 Neformální rozhovory účastníků konference
Neformální rozhovory účastníků konference
První dvě přednášky byly pro všechny společné, poté se program rozdělil na dva proudy ve dvou různých sálech (velkém a malém). V předsálí měli účastníci možnost navštívit stánky firem, které se podílely na přednáškovém programu.
 Stánky v předsálí
Stánky v předsálí
Lesk a bída multifaktorové autentizace
Klasické ověřování uživatelů pomocí jména a hesla je už dávno považováno za bezpečnostně zcela nedostatečné a samo o sobě vhodné jen pro nenáročné případy. Vyššího zabezpečení lze dosáhnout kombinací s dalšími faktory (například generováním nebo posíláním jednorázových hesel, využitím biometrických dat, hardwarovými tokeny…), to ale klade na uživatele vyšší nároky, zdržuje a snižuje pohodlí.
 David Matějů při přednášce o autentizaci
David Matějů při přednášce o autentizaci
Jak to tedy udělat, aby uživatel nebyl nijak významně zatěžován či obtěžován a současně byla zajištěna vyšší úroveň zabezpečení? Možnosti v této oblasti popsal při své přednášce David Matějů. Hovořil o cestě, která z uživatelského pohledu využívá primárně jméno a heslo, ale „pod kapotou“ se provádějí i další ověření.
Od jednoduchých hesel k více faktorům a zase zpět
Na počátku se především překonávala nedůvěra uživatelů k informačním technologiím. Pro ověřování uživatelů – pokud se vůbec provádělo (což v dávnějších dobách nebylo úplně pravidlem) – se využívalo uživatelské jméno v kombinaci s heslem, často jednoduchým.
Protože jednoduchá hesla nepřinášejí příliš velkou ochranu, přišly různé politiky pro hesla (minimální délka, použité znaky, vyloučení slovníkových hesel, intervaly pro změnu apod.). Uživatelům to působilo komplikace, proto často reagovali „po svém“ a hesla si začali různě zapisovat, často třeba na onen pověstný papírek nalepený na monitoru.
Reálně vyšší zabezpečení přinesla vícefaktorová autentizace – ale opět na úkor pohodlí uživatelů. „Používal jsem hardwarový token docela hodně,“ říká David Matějů, „každou chvíli jsem ho ale zapomínal v autě nebo někde v tašce. A když jsem se pak chtěl přihlásit do informačního systému, tak jsem ten token musel hledat, jinak jsem se přihlásit nemohl – přestože jsem to byl já a ten systém mohl vědět, že jsem to já.“
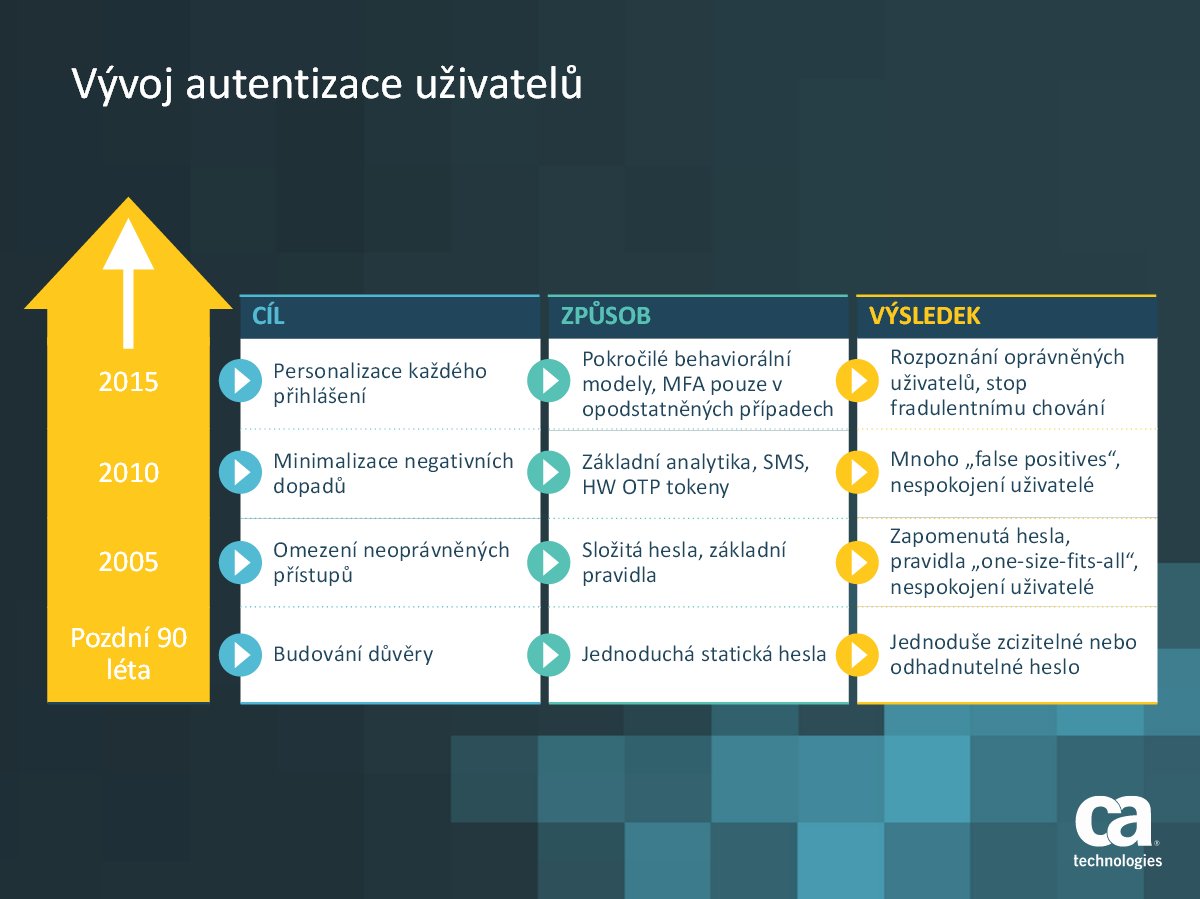 Vývoj autentizace uživatelů (zdroj: prezentace k přednášce)
Vývoj autentizace uživatelů (zdroj: prezentace k přednášce)
Další úrovní jsou behaviorální modely – systém analyzuje a porovnává vzorce chování uživatele. A teprve pokud identifikuje vyšší riziko, zapojí do ověření další faktory. Jinak se použije jen jednoduché ověření, typicky klasickým jménem a heslem.
Bezpečné a přitom snadno použitelné ověřování
Pro volbu řešení ověřování uživatelů jsou důležité jak parametry související s vlastním ověřováním (míra falešných pozitivních i negativních výsledků – tedy jak často není odhalen neoprávněný uživatel, resp. je za podezřelého považován uživatel oprávněný), tak i prostředí, pro které se ověření provádí. Jiná míra zabezpečení bude potřeba pro systémy nedůležité (např. prohlížení jídelníčku podnikové kantýny) a pro systémy s vysokou důležitostí (provádění velkých finančních transakcí).
Z praktického hlediska by mělo být ověřování pro uživatele jednoduché. To zahrnuje jak vlastní přihlašování (a to, co probíhá v pozadí), tak například i možnost snadné změny hesla a řešení jeho zapomenutí (bez nutnosti podstupovat nějaké složité procesy). Důležitá je také snadná migrace na nové, bezpečnější řešení a v neposlední řadě také proporcionalita nákladů k požadované bezpečnosti.
Je také vhodné v reálném čase přizpůsobovat úroveň zabezpečení tomu, v jak citlivé části systému uživatel pracuje. Příkladem může být, že třeba pro provádění platebních příkazů v bankovním systému jsou nároky na ověření uživatele vyšší než pro pouhé prohlížení seznamu transakcí.
 Malý přednáškový sál na konferenci ITSW
Malý přednáškový sál na konferenci ITSW
Nelze zapomenout také na různost zařízení, z nichž se k systému přistupuje: „Všichni tady jedeme z mobilů, tabletů a podobných zařízení. Takže byste měli možnost se i z nich silně ověřit do určité části informačního systému.“ Optimální též je, aby se heslo nikde neukládalo a nikam neposílalo.
Co a jak se ověřuje
Při správné realizaci ověřování záleží na tom, odkud uživatel přistupuje a co se snaží dělat (a v jakém kontextu – viz dále). Na základě toho se vypočítá riziko dané činnosti a buď se vyžádá silná autentizace, nebo potřeba nebude (což je většina případů) a při ověření si bude možné vystačit se jménem a heslem.
 „V hlavní roli je kontext“ (zdroj: prezentace k přednášce)
„V hlavní roli je kontext“ (zdroj: prezentace k přednášce)
Pro vyhodnocení rizikovosti lze využívat více než 60 různých indicií. Patří mezi například čas přístupu, lokalita, způsob připojení, identifikátor zařízení, používání anonymizérů, historie chování uživatele v systému (co dělal dříve a co se snaží dělat teď, jaká zařízení používal, odkud se připojoval…) atd.
Výsledky v praxi
Ukazuje se, že stačí používat silné ověření jen u malé části přihlašování uživatelů a přitom se podchytí podstatná část nekalých aktivit. Pokud se například sekundární (silné) ověření použije jen u 5 % případů, zachytí se 85 % pokusů o neoprávněný přístup. Při použití u 30 % případů je míra zachycení 95–98 %.
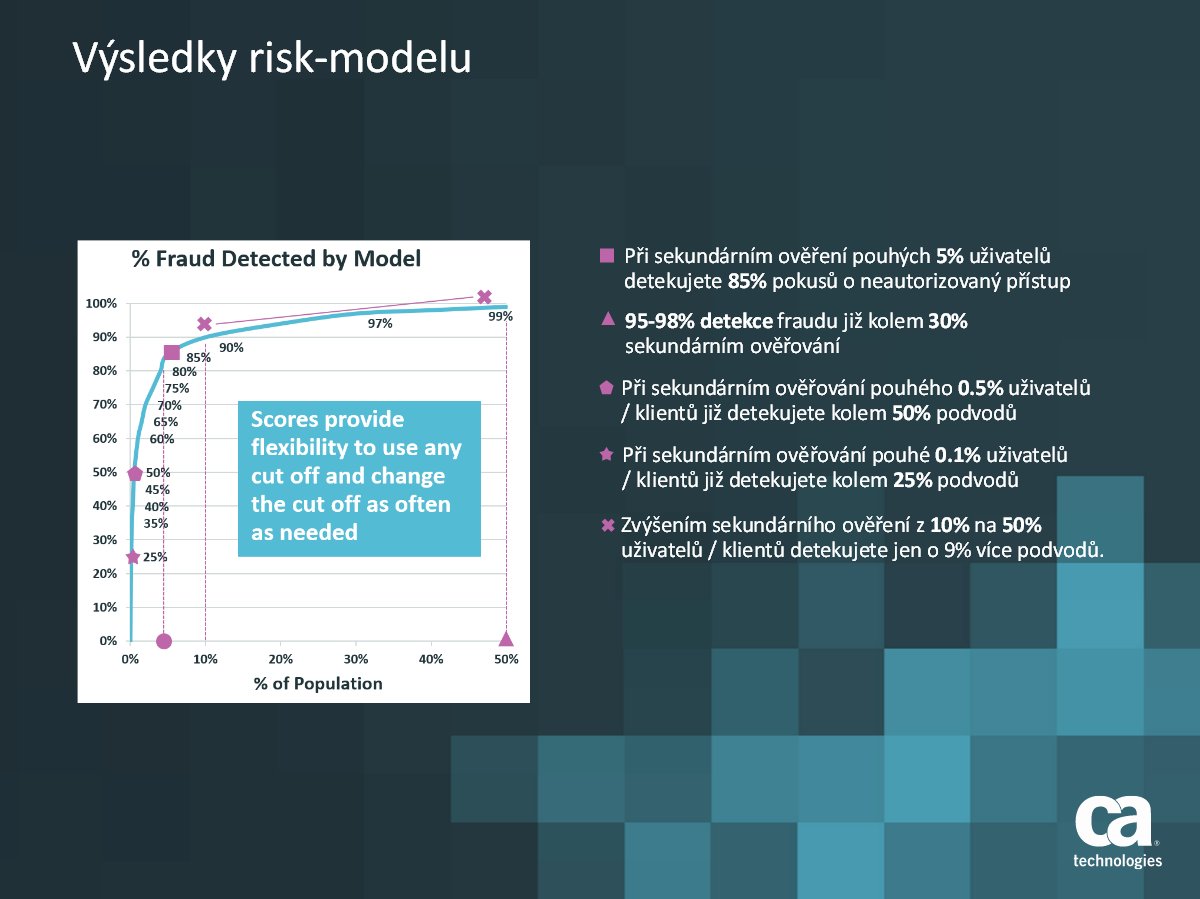 Graf účinnosti pro různou četnost sekundární autentizace (zdroj: prezentace k přednášce)
Graf účinnosti pro různou četnost sekundární autentizace (zdroj: prezentace k přednášce)
Zhruba polovinu nekalé činnosti lze odhalit při silném ověřování 0,5 % případů a dokonce při snížení na 0,1 % případů se stále odhalí okolo 25 % podvodů. I velmi šetrné (k uživatelům) používání sekundárního ověřování je tedy velmi účinné z bezpečnostního hlediska.












