
OCR pro domácí použití
OCRFeeder je, jak již název napovídá, program určený pro optické rozpoznání znaků a jejich převod do digitální podoby. Nejedná se přímo o program jako takový, ale o grafickou nástavbu pro více OCR programů. Díky této metodě je možné pomocí skenování digitalizovat tištěné texty, s nimiž je poté možno pracovat jako s normálním počítačovým textem. Program je vybaven GTK grafickým prostředím a můžete ho stáhnout z domovských stránek, více informací se také dozvíte na stránkách autora Joaquima Rocha. V některých distribucích ho také najdete v repozitáři.
A jak to vlastně funguje?
Představte si že máte nějaký text uložený v obrazovém formátu, jako je JPG, PNG atd. Možné je také použít PDF. Pak není nic snazšího než spustit OCRFeeder, v levém horním rohu kliknout na zelenou ikonu se symbolem plus a přidat požadovaný obrázek. Další možností je připojení vašeho skeneru a provést naskenování textu přímo z programu. Poté se vám naskenovaný nebo načtený text objeví v prostředním poli programu.
 Po načtení obrazu je možné použít odstranění deformace obrazu a ulehčit načítání
Po načtení obrazu je možné použít odstranění deformace obrazu a ulehčit načítání
Zvýrazněním pomocí myši vyberete text, který chcete převést do požadovaného formátu. Na vybranou máte prostý text, ODT nebo HTML. Pokud by jste chtěli převádět celý dokument, je jednoduší kliknout na tlačítko Rozpoznat dokument. Dojde k automatickému výběru textu, který bude označen modrou barvou, a k výběru obrázků, které jsou označeny barvou zelenou. Text, který vyberete, se zobrazí ve výřezu v pravém sloupci nahoře.
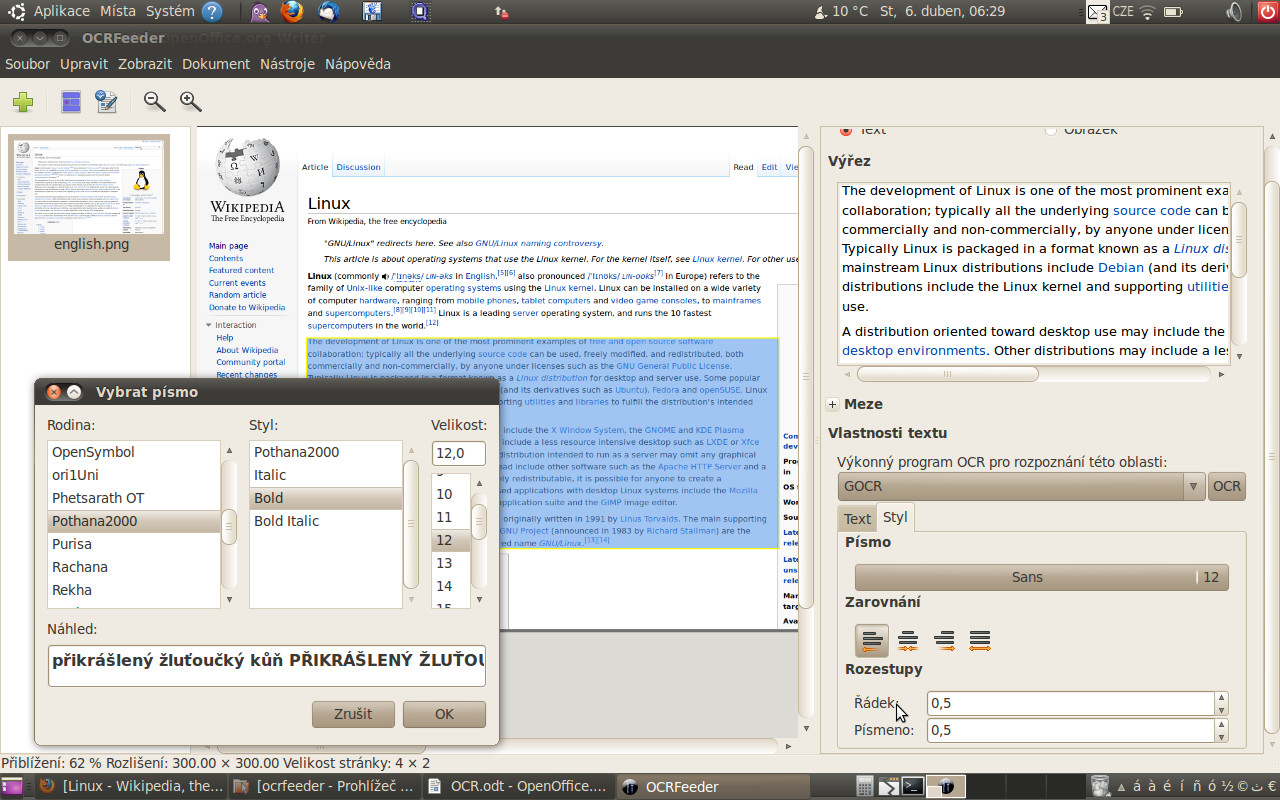 Příprava načteného textu před před převodem pomocí OCR
Příprava načteného textu před před převodem pomocí OCR
V pravém sloupci dole zvolíte kartu Styl, na ní vyberete písmo a jeho velikost a uspořádání textu ve vytvářeném dokumentu. Před samotným naskenováním textu zvolíte požadovaný program, kterým chcete převod provést. Jako výchozí je nastaven program GORC. Dále máte možnost zvolit a použít Tesseract a já jsem dodatečně přidal Guneiform. Poté kliknete na tlačítko OCR. Dojde k převedení textu, který jste vybrali, a převedený obraz se zobrazí na kartě Text.
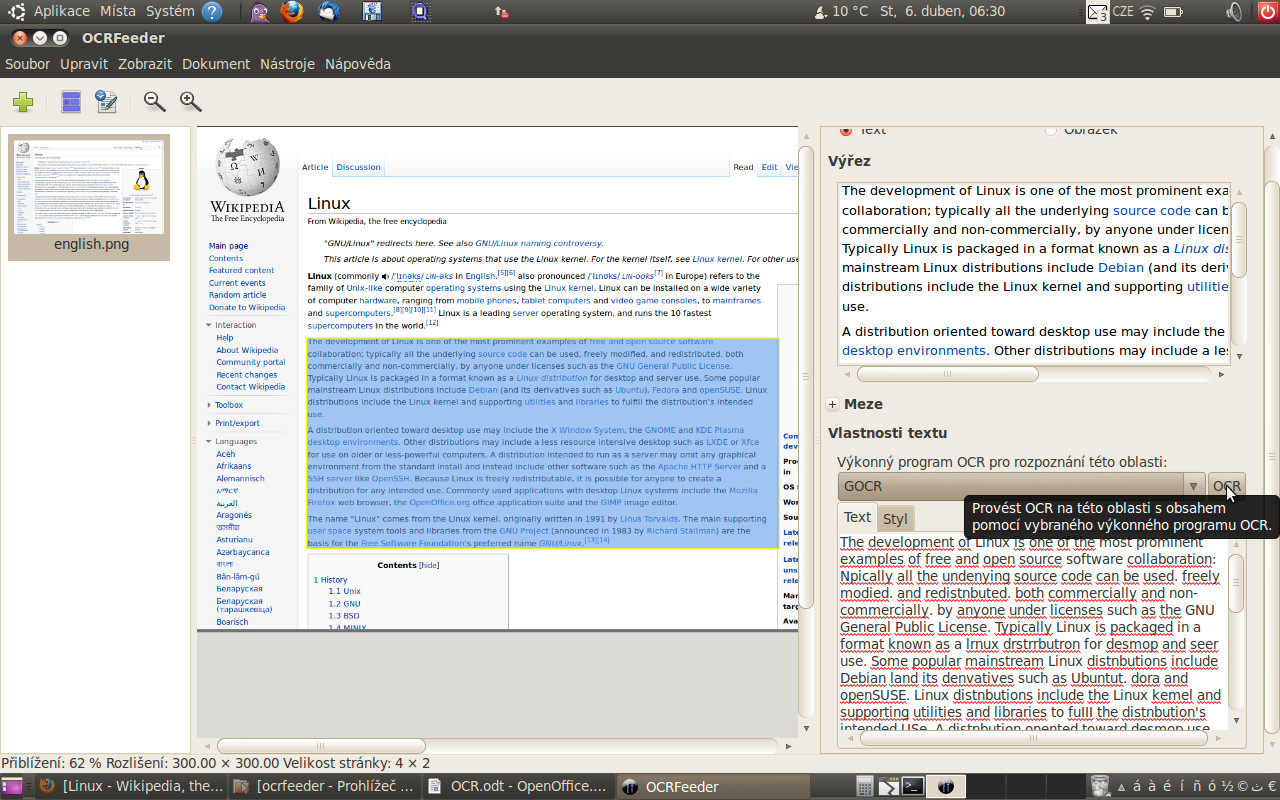 Po provedení OCR je vše připraveno pro export do požadovaného formátu
Po provedení OCR je vše připraveno pro export do požadovaného formátu
V textu je pak možné provádět různé editace, jako je například úprava chybně rozpoznaných znaků a nebo kontrola překlepů. Možnost kontroly překlepů je v programu již implementována a je automaticky nastavena dle vašeho systému. Před samotným exportem stránky do ODT nebo jiného vámi zvoleného formátu je ještě nutné provést samotné nastavení této stránky. To provedete tak, že v liště nabídky kliknete na Úpravy | Upravit stránku a zvolíte parametry. Nejčastěji to bude formát A4 a ještě doporučuji zatrhnou volbu Nastavené pro všechny následující převody.
 Pokud zapomenete na tento krok, převedete výběr na přednastavený formát 4,3 × 2,7 cm, což je taková mini stránka
Pokud zapomenete na tento krok, převedete výběr na přednastavený formát 4,3 × 2,7 cm, což je taková mini stránka
Pak už jen stačí kliknout na tlačítko exportu ODT a uložit požadovaný text. Pokud byste však chtěli dokument uložit v jiném formátu, klikněte v liště na Soubor | Export a nastavte požadovaný formát exportu. V tomto případě jsme převedli text do formátu ODT a po uložení už jen zbývá upravit rámec textu a můžete s ním začít pracovat. Stále tady hovořím pouze o textu, samozřejmostí je ovšem i převod obrázků, nicméně pro nenáročnost této činnosti, tuto část vynechávám. Postup je stejný jako u textu, a to bez potřeby výše zmiňovaných úprav.
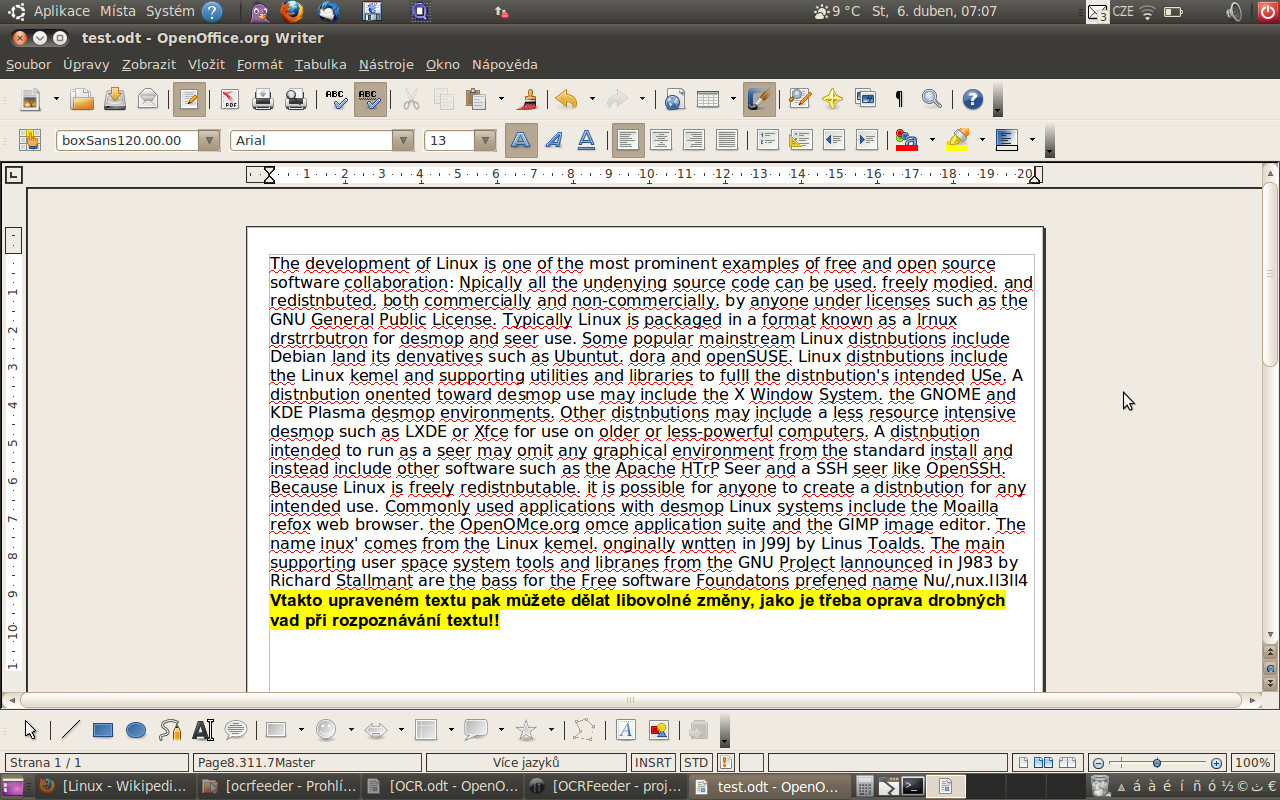 Je hotovo, text je převeden a můžete s ním libovolně pracovat
Je hotovo, text je převeden a můžete s ním libovolně pracovat
Česká diakritika schází
Nic není ale tak dokonalé, jak se může na první pohled zdát. Záměrně jsem pro tento článek zvolil převod anglického textu, jelikož česká diakritika není bohužel podporována a jak jste si určitě všimli, ani anglický převod není bez chyby. Snažil jsem se proto provést konfigurace jednotlivých výkonných programů, ale bez úspěchu. Absence podpory českých znaků bude zcela určitě důvod, proč tento program nebude masově nasazen na strojích českých uživatelů.
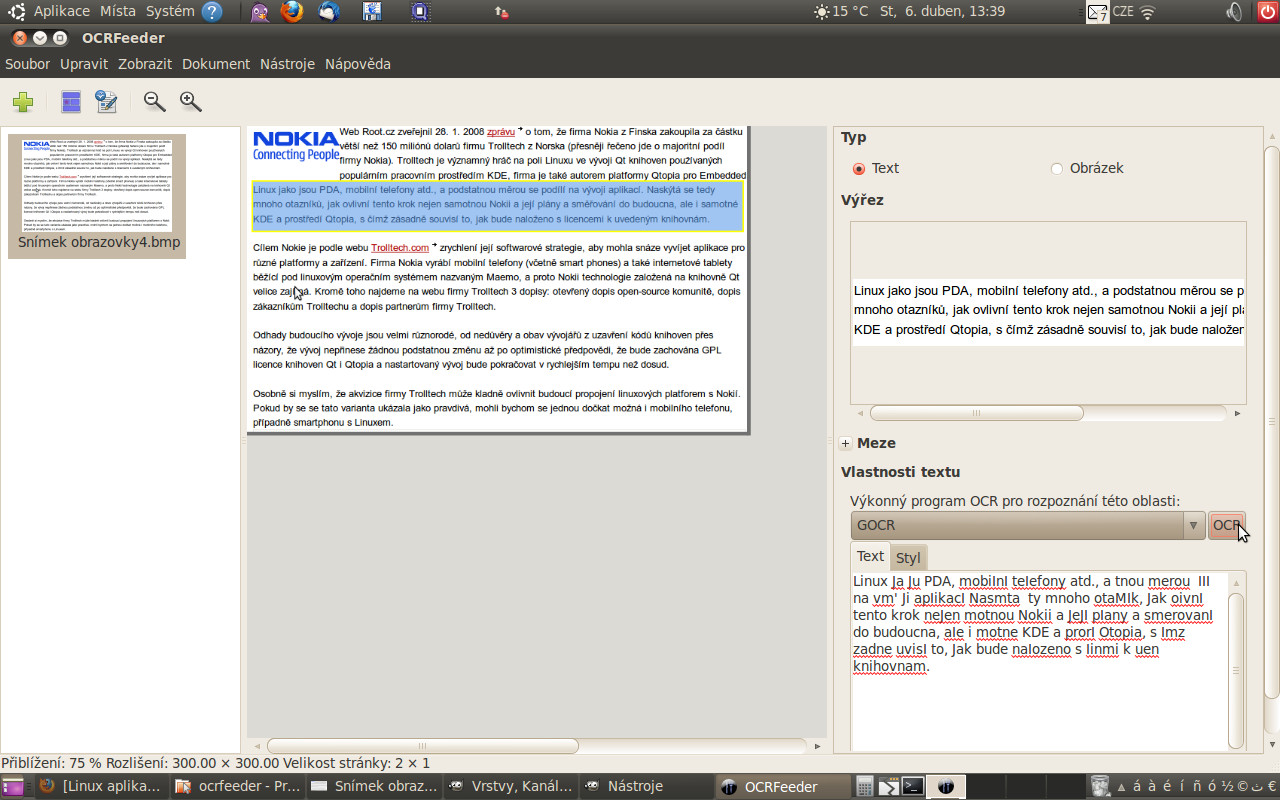 Než tohle, to raději ruční přepis
Než tohle, to raději ruční přepis
Jinak je nutné OCRFeeder pochválit za jednoduchost a přehlednost a nám nezbývá nic jiného než čekat na to, až se alespoň jeden z podporovaných OCR programů naučí číst česky.













