Pro zpřehlednění očísluji kroky pracovního postupu:
- pořízení surových dat a jejich uložení,
- konverze surových dat do vhodného formátu a jiné přípravy k zpracování,
- vlastní zpracování dat,
- „zahození“ málo významných dat,
- export grafu ze skriptu, import grafu do programu Gephi,
- příprava vizualizace, nastavení vzhledu, získání finální grafiky,
- diskuze dosažených výsledků.
Krok 1 : Pořízení dat
Budu zpracovávat dva zástupce krásné literatury a dva příklady odborných textů.
- Dílo Babička ve volně dostupné verzi zveřejněné serverem Literární doupě.
- Dílo Dobrodružství Toma Sawyera ve volně dostupném anglickém znění podle redakce projektu Gutenberg.
- Namátkou vyberu z českojazyčné Wikipedie citace z deseti článků, které pojednávají o chemických prvcích. Celková délka citací bude přibližně padesát normostran.
- Stejně připravím také odborný anglický text.
Neuváženým nakládáním s daty nebo zveřejněním výsledků zpracování nezřídka hrozí porušení práva autorského a k databázi, dále toto počínání může být i eticky sporné stran zasahování do soukromí. U zvolených dat nic podobného nehrozí.
Nahrání dat do skriptu je prosté čtení souborů kódovaných jako UTF-8, proto bude potřeba knihovna pro správné dekódování. U XML souborů by byl potřeba XML parser, u databáze databázový konektor, u obrázku knihovna pro grafiku...
Poznámka: Zdrojový kód popisovaného skriptu si můžete stáhnout a vyzkoušet. Odkaz na skript a na ukázkový projekt najdete na konci článku.
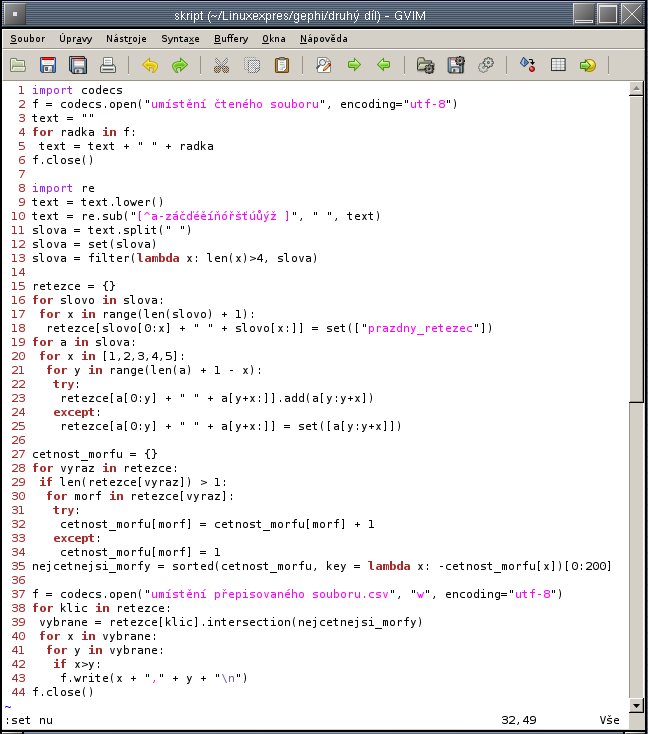
Komentáře k prvním šesti řádkům zdrojového kódu:
- Importuji modul codecs, jímž budu přistupovat k souboru.
- Zadám správné kódování a otevřu textový soubor.
- Do proměnné text vložím prázdný řetězec. Proměnnou později naplním textem z otevřeného souboru.
- Čtu jednotlivé řádky z textového souboru.
- Jednotlivé řádky připojuji mezerou na konec textového řetězce. Operátor sčítání znamená u řetězců, že se druhý řetězec "přilepí" (concatace, zřetězení) za první.
- Přečtený soubor zavírám.
V některých verzích platformy Python se řetězce v UTF kódování musí značit prefixem u. Řetězec u"ů" je v příslušných verzích chápán jako jednoznakový UTF-řetězec obsahující písmeno ů, neprefixovaný řetězec "ů" je chápán jako dvouznaková posloupnost bytů s hodnotami 192 a 172. Nové verze Pythonu defaultně používají UTF-řetězce i bez prefixu u. Česká spřežka ch se v obou kódováních počítá jako dva znaky.
Krok 2: Příprava dat
Text je nyní nutno "vyčistit" od diakritických znamének a extrahovat jednotlivá relevantní slova. Komentáře osmého až třináctého řádku zdrojového kódu:
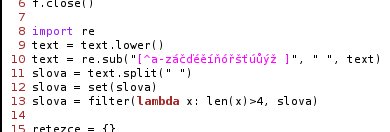
- Importuji modul regex (regulární výrazy), jímž "vyčistím" originální text.
- Převádím všechna velká písmena na malá.
- Surový text musíme napřed "zbavit" uvozovek a jiných diakritických znamének, číslic a od řádkování. Výsledný řetězec by se měl skládat jen ze znaků a, á, b, c, č ... x, y, ý, z, ž a znaku mezera. Příkaz
text = re.sub("[^a-záčďéěíňóřšťúůýž ]", " ", text)znamená: „V řetězci nahraď všechny znaky, vyjma znaků explicitně vyjmenovaných, mezerou. Vyjmenované ignorované znaky jsou znaky mezera a úplná malá česká abeceda, tedy nadmnožina znaků anglické abecedy.“ (Znak mezera je uveden jen pro přehlednost kódu, neboť náhrada mezery mezerou tak jako tak dává identitu.) - Jednolitý řetězec se v mezerách "rozřeže" do posloupnosti jednotlivých slov. Prázdná slova, vzniklá z dvou mezer za sebou, se zruší na řádku třináct.
- Řádek dvanáctý změní typ proměnné slova (posloupnost) na typ množina. Opakující se řetězce se během přetypovávání uloží právě jednou, poněvadž Python chápe řetězce jako hodnotu, nikoliv jako ukazatel. Tím se ztratí jak informace o pořadí slov, tak informace o četnosti výskytu. To však nebude vadit.
- Tento řádek smaže příliš krátká slova. Předpokládám totiž, že se smažou zkratky, předložky a citoslovce.
V třináctém řádku se objevuje takzvaný lambda výraz. Lambda výraz není nic jiného než zhuštěný zápis funkce. Výraz (lambda x: f(x))(y) je přesně totéž co f(y), výraz (lambda x,y : f(x,y))(z,w) je f(z,w), výraz (lambda x: f(x,x))(y) je f(y,y)... Takto zapsaným dosazováním se dají dynamicky vytvářet za běhu programu funkce, což předvádí následující výstřižek z terminálu Pythonu.

Klíčovým slovem def se uvozují funkce. Zde definujeme funkci zvanou mocnina mající jeden argument. Jak vidno, mocnina je rekurzivní funkce vracející lambda výraz, tedy nově vytvořenou funkci. Do proměnné třetí mocnina je uložen výraz mocnina(3). Výraz mocnina(3)(x) se rovná výrazu x * (lambda y: y*mocnina(3-1)(y))(x), to se rozvine na x*x*(lambda y: y*mocnina(2-1)(y))(x), to činí x*x*x*(lambda y: mocnina(0)(y))(x), což není nic jiného než lambda x: x*x*x*(lambda y: 1)(x) a konečně se výraz zjednoduší na x*x*x. Do proměnné třetí mocnina se dostala funkce vyčíslující třetí mocninu, aniž by tuto funkci programátor byl zapsal.
Komentář třináctého řádku:
- Funkce len značí délku hodnoty proměnné, zde počet znaků. Filtr vyjme všechny položky, pro něž lambda výraz vrátí logickou nepravdu. Tudíž se na desátém řádku z posloupnosti slova odfiltrují všechny jednoznakové, dvouznakové, tříznakové a čtyřznakové řetězce, a ponechají se jen řetězce o minimálně pěti znacích.
Co vlastně budu dělat?
Čeština, jakož i angličtina a většina evropských jazyků příslušejí k jazykům takzvané indoevropské jazykové rodiny, jež pochází z jednotného prajazyka. V oblasti morfologie sdílejí indoevropské jazyky, potažmo jejich historické formy, následující rysy. Slova se skládají z předpony, kořene, přípony a koncovky. Předpony, kořeny, přípony ani koncovky nemají pevný počet znaků. Koncovka může být i nulová (např. bez žen).
Předpona a koncovka mohou být homonymní (např. u ve slovese ujdu). Předpony a přípony zpravidla slouží slovotvorbě, a tak jich může být v jednom slově obsaženo více. Předpona ani přípona nemusí být ve slově nutně přítomna. Každé ohebné slovo má však vždy právě jednu koncovku, kterou se vyjadřují současně všechny gramatické kategorie.
Například koncovkou ami se tvar ženami naráz hlásí k slovnímu druhu, rodu, vzoru, pádu i číslu, aniž by ami bylo možno rozčlenit na část pádovou a část číselnou. Skloňováním se dále vyjadřují různá pojetí téže předložky (např. "statické" na stole, "dynamické" na stůl). Často se před koncovku vkládá zvláštní kmenotvorná přípona (např. et, at u vzoru kuře). Někdy druhotně koncovky a přípony způsobují drobné změny v kořeni (např. změna délky, hrách a bez hrachu).
Pouze u malé uzavřené skupiny vysoce frekventovaných slov se v různých tvarech vyskytují různé kořeny (např. já a o mně). Ohýbají se všechna jména, zájmena, číslovky a slovesa. Existuje několik sad koncovek pro časování i skloňování, přičemž pouhá znalost koncovky často postačuje k určení slovního druhu a vzoru. Celkově nalézáme velmi rozsáhlý repertoár koncovek i přípon. Časté jsou různé nepravidelnosti.
Generování tvarů od jednoho kořene můžeme ve většině případů formálně popsat tak, že se obměňují konce řetězců (udělaný, udělaná), začátky řetězců (prodělala, vydělala) nebo vnitřky řetězců (nevydělala, neprodělala). Nejpřímočařejší by bylo zvolit slova za uzly grafu, slova shodující se v mnoha znacích spojit hranou a za váhu hrany zvolit míru podobnosti obou slov. Tento přímočarý postup, jenž nepoužijeme, je velmi konkrétní, proto snadno pochopitelný:
- Uzly jsou ztotožněny přímo s prvky zkoumané množiny slov.
- Existence hrany vyplývá přímo z vlastností dvou uzlů.
- Podobně i váha hrany nezávisí na vnějších okolnostech.
Některé z obměn jsou plně gramatizované. Mnohým morfům náleží konkrétní gramatické funkce. Morfů s gramatickým a slovotvorným významem je logicky řádově méně než kořenů slov. Střídá-li se podřetězec s jiným podřetězcem nápadně často, lze rozumně předpokládat, že oba podřetězce nesou konkrétní gramatický nebo slovotvorný význam.
Tuto anomálii lze strojově identifikovat. Budeme-li hledat v běžném textu nejfrekventovanější znakové podřetězce, nalezneme převážně morfy s gramatickým či slovotvorným významem. Přirozené tedy bude za uzly grafu zvolit nejfrekventovanější podřetězce.
Některé významy těchto nejfrekventovanějších morfů se vylučují, tedy určité podřetězce "zakazují" přítomnost jiných podřetězců v témže slově. Například řetězec ium, jenž značí slovo přejaté, se bude "zakazovat" s řetězcem před, jenž je předponou ve slovech domácích. Mohli bychom hranami spojovat dvojice častých podřetězců, jež se téměř nikdy nevyskytnou současně v jednom slově. (Tento postup by vyžadoval pro dvojice velmi komplikovaně predikovat statisticky významnou míru koincidencí, proto naznačenou myšlenku zavrhněme.)
Podobně se zakazuje ami a ský, protože slovo nemůže být simultánně podstatným i přídavným jménem, zato častá bude záměna mezi ou a ský (ženou, ženský). Ale ještě častější bude substituce ou s a (ženou, žena), neboť toto se provádí u veškerých substantiv vzoru žena. Hranami spojme podřetězce, u nichž se vyskytuje takováto substituce mezi slovy zkoumaného textu. Vahou hran budiž počet dokladů příslušné substituce v analyzovaném textu. Tento postup, jenž použijeme, je více abstraktní:
- Uzly nejsou ztotožněny s prvky zkoumané množiny slov.
- Existence hrany nezávisí na vlastnostech dvou uzlů. Vyplývá až z vnější okolnosti, že lze vyhledat v množině slov "svědky" záměny.
- Též váha je nezávislá na uzlech samých, musí se "vydestilovat" z celé množiny slov.
Mezi výhody abstraktnějšího přístupu patří třeba snížení počtu uzlů, spjatost uzlů s gramatickým významem a celkově srozumitelnější graf.
Krok 3: Zpracování dat
Složenými závorkami se v Pythonu značí datová struktura typu slovník. Slovník se zapisuje jako {prvni_klic:prvni_promenna, druhy_klic:druha_promenna, treti_klic:treti promenna}. K hodnotě uložené v slovníku se přistupuje zápisem nejaky_slovnik[nejaky_klic]. Ve for-cyklech se slovník iteruje přes množinu svých klíčů.
Vztahy definující graf bude udávat slovník pojmenovaný retezce. Ve slovech budu podřetězce nahrazovat mezerou, která bude fungovat jako "žolíkový" znak. Žolíkové řetězce budou klíči slovníku, pod nimiž budou uloženy nahrazené podřetězce. Získá-li se nahrazováním ze dvou různých slov slovo stejné, získá se doklad o záměně dvou řetězců. Vybudování slovníku retezce - toť podstata třetího kroku.
Po zpracování českého odborného textu se kupříkladu pod klíčem "sloučen" bude skrývat množina prvků "inou", "y", "iny", "inách", "ině", "ím", "inu", "in", "inám", "ém", "inami", "ina". Provedu-li zpětně dosazení, získám tvary doložené v korpusu (sloučeninou, sloučeny, sloučeninách...). Tím jsme se přesvědčili, že v textu byly nalezeny záměny "inou" s "y", "inou" s "iny", "y" s "iny" atd.
Následující instrukce (řádky 15 až 25) zkonstruují slovník retezce takový, že:
- Klíči budou řetězce obsahující právě jeden znak mezera.
- Hodnotami klíčů budou množiny řetězců o nejvýše pěti znacích. (Neočekávám, že by obvyklé morfy mívaly přes pět znaků.)
- Bude-li pod klíčem K uložena množina obsahující řetězec "prazdny retezec", pak řetězec, jenž vznikne vynecháním mezery z K, bude prvkem množiny slova. (Popisné označení "prazdny retezec", místo prázdného řetězce, volím kvůli snadnému převodu dat do formátu csv.)
- Bude-li pod klíčem K množina obsahující řetězec A, pak řetězec, jenž vznikne náhradou mezery v K řetězcem A, bude prvkem množiny slova.
- Množina klíčů ani uložené hodnoty již nepůjdou při zachování předchozích podmínek rozšířit. Jinak řečeno slovník
retezecbude maximální možný.
Na řádcích patnáct až osmnáct splním současně podmínky 1, 2, 3 a 5. Komentáře řádků:

- Slovník
retezceinicializuji prázdným slovníkem. - Procházím všechny prvky množiny slova.
- Proměnná x probíhá všechny pozice ve slově.
- Vkládám záznam do řetězce.
Syntaktické poznámky:
- Řez
A[x:y]udává interval. Konkrétně u UTF-řetězceAjeA[x:y]podřetězec mezi znakem na x-té pozici a znakem na y-té pozici. - Zápis
A[x:]je synonymemA[x:len(A)]. - Posloupnost
range(x)je posloupností celých nezáporných čísel ostře menších než celé číslo x. - Zápis
[1,2,3,4,5]značí posloupnost uvedených čísel. - Zápis
set([1,2,3,4,5])definuje množinu uvedením jejích prvků.
Je-li jediným zpracovávaným slovem "babička", získáme slovník {" babička": set(["prazdny_retezec"]), "b abička": set(["prazdny_retezec"]), "ba bička": set(["prazdny_retezec"]), "bab ička": set(["prazdny_retezec"]), "babi čka": set(["prazdny_retezec"]), "babič ka": set(["prazdny_retezec"]), "babičk a": set(["prazdny_retezec"]), "babička ": set(["prazdny_retezec"])}.
Komentáře řádků 19 až 25:
- Viz komentář řádku 16.
- Zpracovávám nejvýše pětiznakové řetězce.
- Viz komentář řádku 17.
- Pythone, pozor, následující instrukce mohou způsobit chybu.
- Snažím se vložit záznam. Chyba nastane, když vkládám do neexistující množiny.
- Pythone, eventuální chybu ošetři následující instrukcí.
- Chyba se ošetří založením množiny a vložením prvku. Odlišné chyby (např. vyčerpání operační paměti) neočekávám.
Je-li jediným zpracovávaným slovem "babička", do slovníku přibudou mimo jiné dvojice "babičk ": set(["a"]), "babič ": set(["ka"]), "babi ": set(["čka"]), "babi a": set(["čk"]), " abička": set(["b"]), " bička": set(["ba"]), " ička": set(["bab"]). Nyní již jen potřebuji získat informaci o nejfrekventovanějších podřetězcích a jejich obvyklých záměnách.
Krok 4: Nalezení významných vztahů
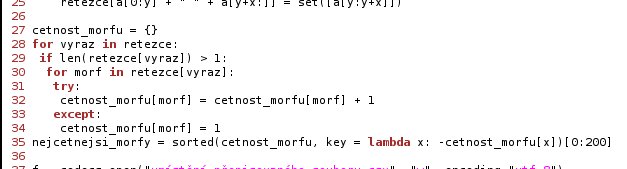
V tomto kroku určím morfy, které nejčastěji vstupují do záměn. Řádky 28 až 34 jsou, kromě řádku 29, analogické řádkům 19 až 25. Řádek 29 zajistí, že jsou započteny jen množiny dosvědčující nějakou substituci.
Konstrukt sorted (35. řádek) setřídí posloupnost podle "velikosti" prvků. V prvním argumentu se předává posloupnost k seřazení. Nepovinný argument key obsahuje funkci jedné proměnné. Do té se dosazují klíče a dle výsledků se řadí posloupnost. Unární minus zajišťuje u číselných hodnot opačný směr řazení, což je ekvivalentní nastavení nepovinného argumentu reverse na hodnotu pravda sorted(cetnost_morfu, key=lambda x: cetnost_morfu[x], reverse=True). Do proměnné nejcastejsi morfy se uloží prvních dvě stě nejlepších morfů.
Krok 5: Export a import grafu
Komentáře zbývajících řádků:
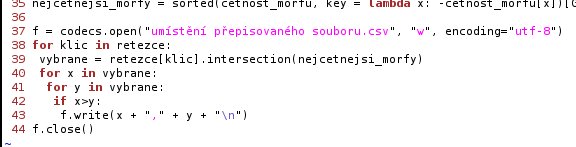
- Otevřu soubor.
- Procházím klíče.
- Do proměnné vybrane ukládám průnik množiny
retezce[klic]anejcetnejsi_morfy. Díky tomu nebudou zpracovávány irelevantní položky. - Procházím hodnoty průniku.
- Znovu procházím hodnoty.
- Řetězce jsou ostře lineárně uspořádané relací
str.__gt__. Výraz x>y je stručný zápisstr.__gt__(x,y). Uspořádání závisí na národních zvyklostech a na kódování. - Připíši na konec souboru nalezenou dvojici a odřádkuji.
- Zavřu soubor.
Výstupem u textu Babička bude posloupnost dvojic ý,é; ý,o; ý,ého; ý,ou; nulova_koncovka,ho; lu,l; ly,lu; ly,l; ých,í; ov,ost; ík,o; ík,ném; o,ném; mi,ch; nulova_koncovka,ho; nulova_koncovka,ne; roz,po; u,nulova_koncovka... Do výstupu se pochopitelně dostanou i náhodné šumy. Například ve slovech slovech příkladem a příjmem bude rozpoznána agramatická dvojice klad, j.
Po úspěšném exportu musíme ještě importovat data do Gephiho.


V uvítacím dialogu otevřu CSV s uloženými daty. Posléze zvolím, aby hrany byly neorientované.
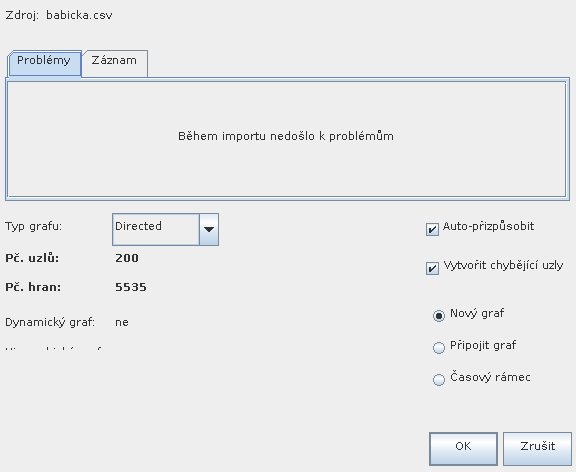
Poznamenejme, že:
- Gephi správně rozdělil záznamy v místě čárek a na řádkových zlomech,
- Gephi ze záznamů o hranách vygeneruje chybějící záznam o uzlech,
- Gephi náležitě počet výskytu hrany interpretoval jako váhu hrany.
Krok 6: Vizualizace
Nyní na kartě Rozložení (viz předchozí díl) vyberu rozložení (layout) fruchterman-reingold. Spustím výpočet, aniž bych změnil parametry. Po chvíli, až se rozložení ustálí, výpočet zastavím.
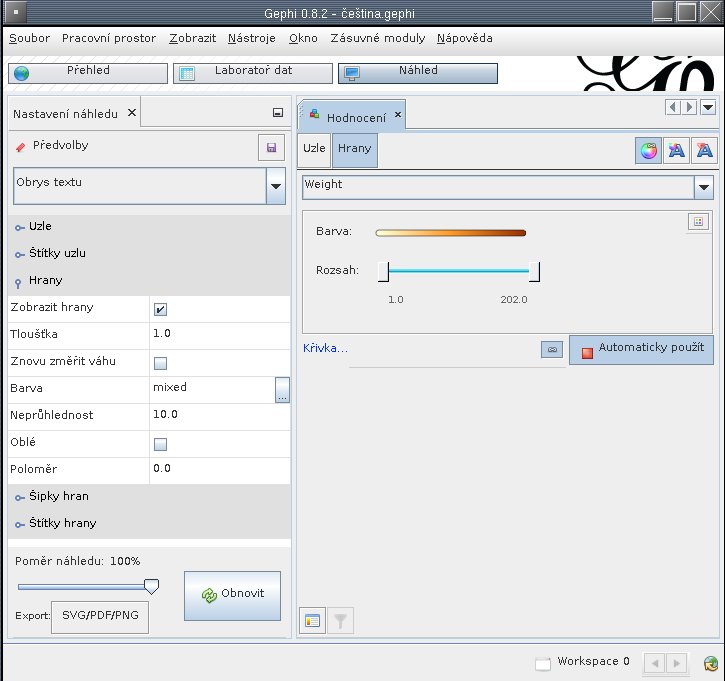
V kartě Nastavení náhledu zruším nastavení oblé hrany (edge curved). Neprůhlednost (opacity) snížím na deset procent. Nastavím typ grafu na obrysy textu (text outline). Otevřu kartu hodnocení (ranking). Nastavím hodnotící parametr hrany na váhu hrany (weight). Nastavím hodnotící parametr uzlu na stupeň uzlu (degree). Velikost popisků nastavím od deseti do čtyřiceti bodů.
Z výběru zvolím první barevnou škálu. Mapování hodnot na škálu se určuje v menu křivky. Pomocí menu křivky bych například mohl zdůraznit mimořádné hodnoty, a potlačit nevýrazné hodnoty. U všech nastavení zvolím samočinnou aplikaci Automaticky použít (auto apply). Ponechám výchozí lineární mapování.
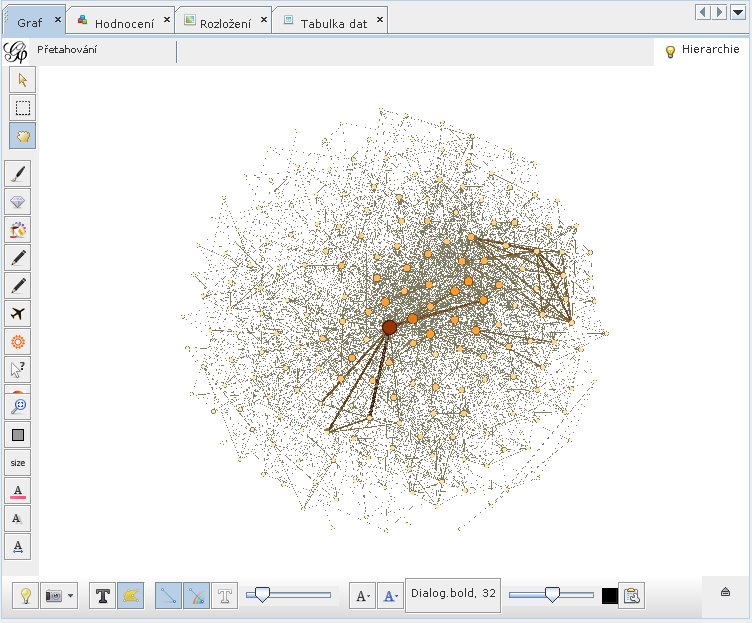
Otevřu kartu Laboratoř dat. Popisek uzlu prazdny retezec je příliš dlouhý, tak mu přepíši popisek na hutnější NULL a identifikátor uzlu na nula.
Konečně v nastavení náhledu poklepu na tlačítko Obnovit náhled. Graf se ihned vykreslí do karty Náhled.
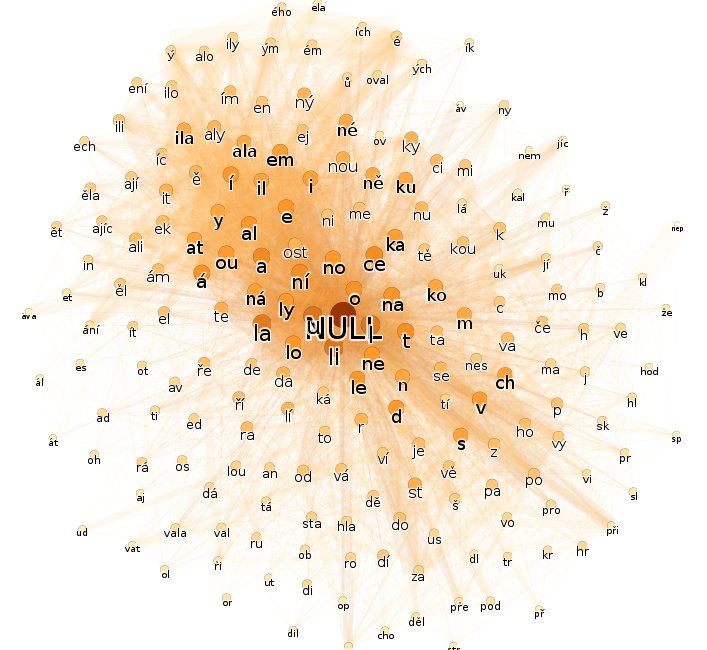
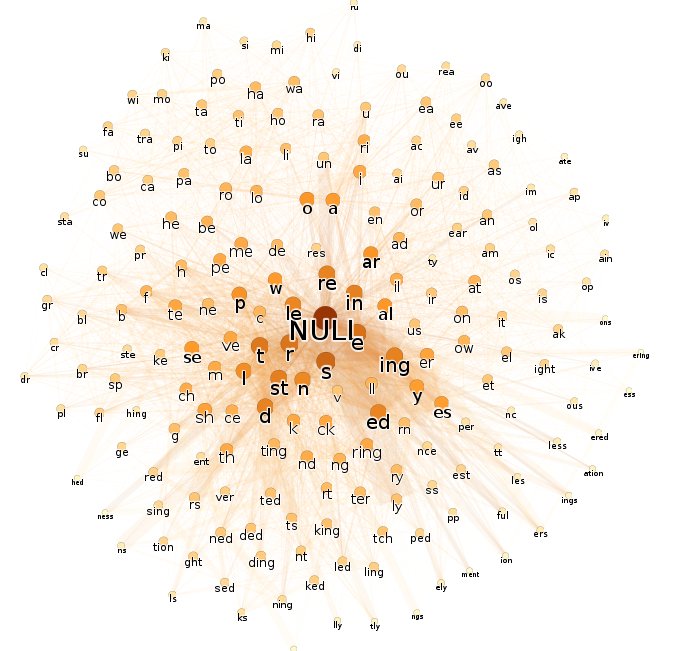
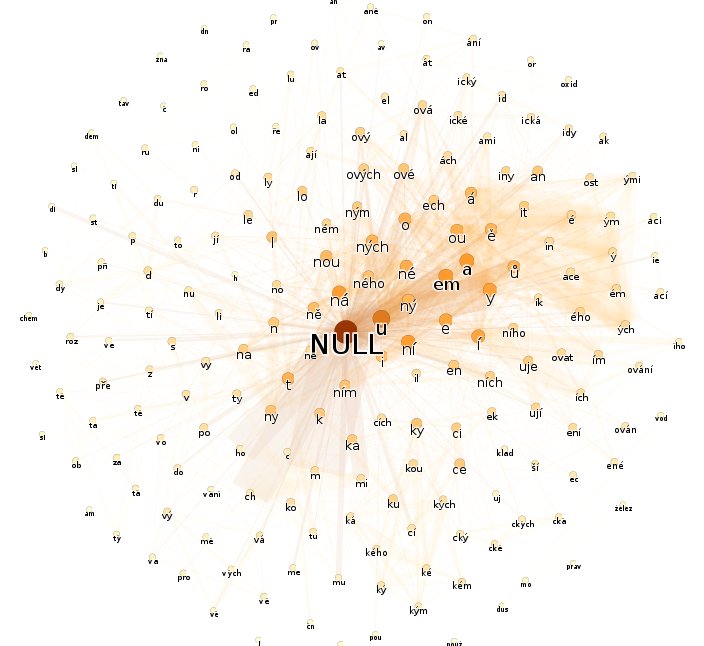
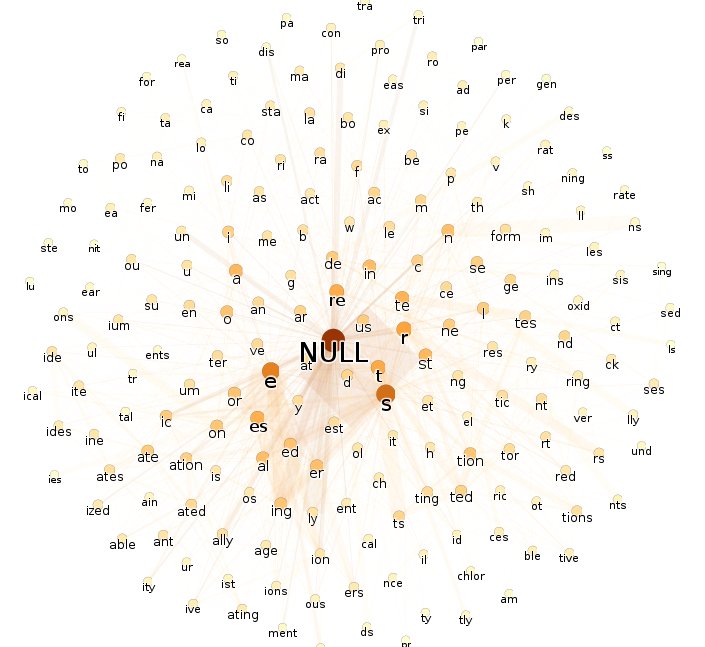
U posledního grafu hrany "přetékají" po okraji. Pokud ve skriptu místo dvou set ponechám pět set uzlů (změna v generujícím skriptu), již hrany nebudou "vyhřezávat". U angličtiny by zvýšení počtu uzlů mohlo vést ke stavu označovanému teorií strojového učení za přeučení (overlearning).

Podotkněme, že v čtvrtém kroku došlo nejen k redukci počtu uzlů, nýbrž i:
- Řádek 29 zamezil započítávání případů, kdy není doložena žádná substituce.
- Řádky 32 a 34 určují váhu. Kdybych místo jedničky inkrementoval výraz
len(retezce[vyraz]), zvýhodnil bych mnohačetné záměny. - Později řádek 42 zabránil dvojitému ukládání dvojic.
- Týž řádek zamezil zamezil uloženízamezil uložení hran spojujících uzel se sebou samým (smyčky nulové délky).
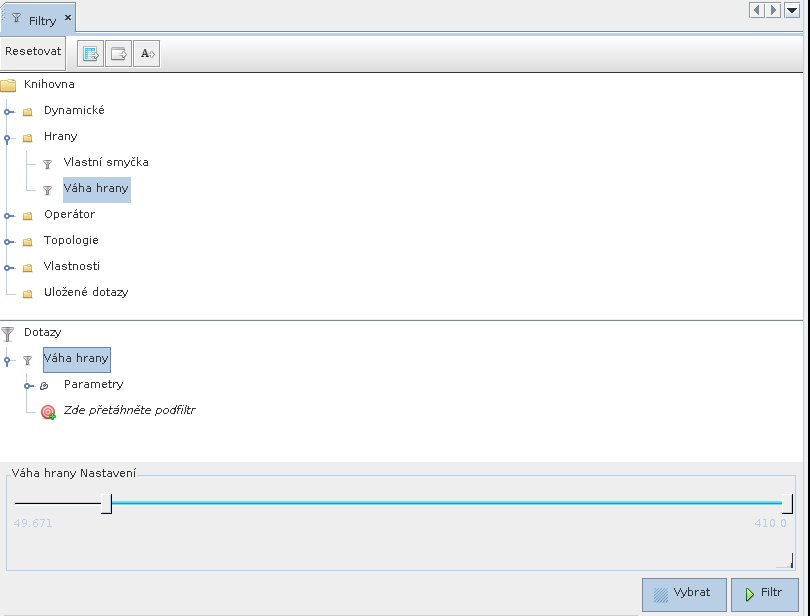
Jisté základní filtrace provádějí funkce na kartě Filtry. Nyní odfiltruji hrany s vahou pod čtyřicet.
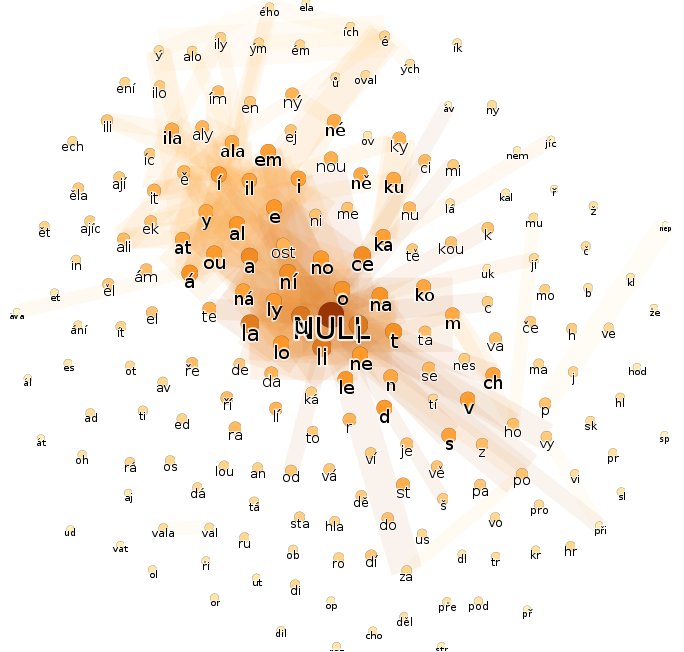
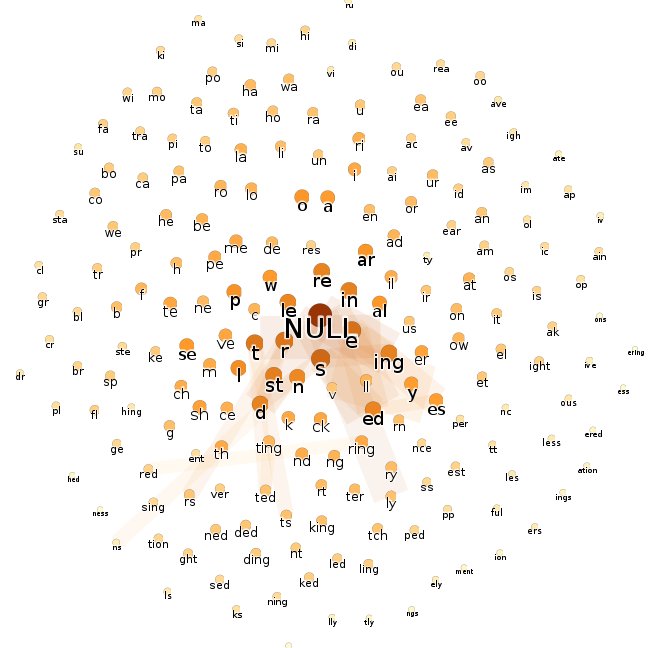
Nyní u českého chemického textu otevřu kartu Tabulka dat a vytvořím u uzlů nový sloupec, nazvaný Slovní druh. Tam vepíši poznámku, s jakým slovním druhem ta která skupina znaků asi (bez záruky) souvisí. V kartě Oddíl naleznu základní statistiku četnosti a kruhový graf.
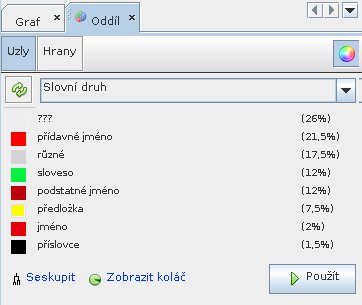
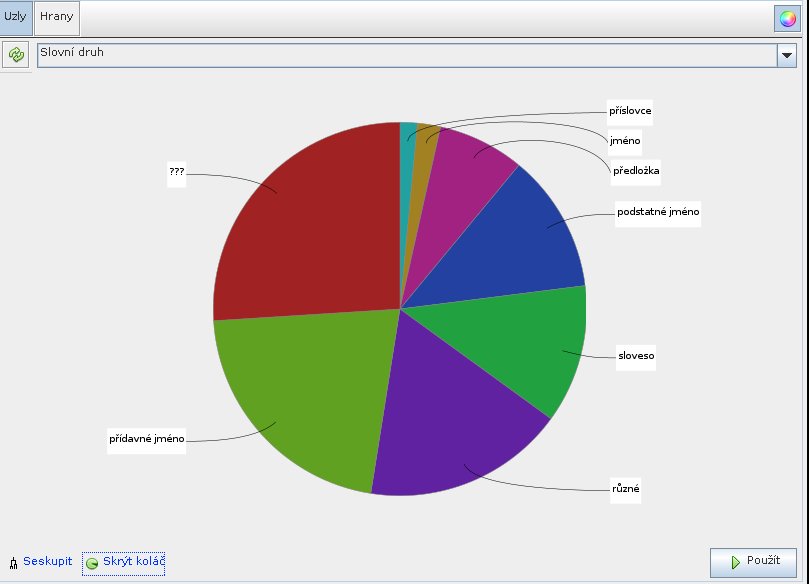
Barvy přiřazené jednotlivým možnostem lze změnit. Nyní na kartě Hodnocení změním hodnotící parametr na nově vytvořený sloupec Slovní druh a vykreslovací barvu sváži s hodnotou v sloupci Slovní druh. Nyní opět obnovím náhled.
Na závěr projekty uložím ve formátu .gephi.
 Ukázka spuštění skriptu
Ukázka spuštění skriptu
Krok 7: Zhodnocení dosažených výsledků
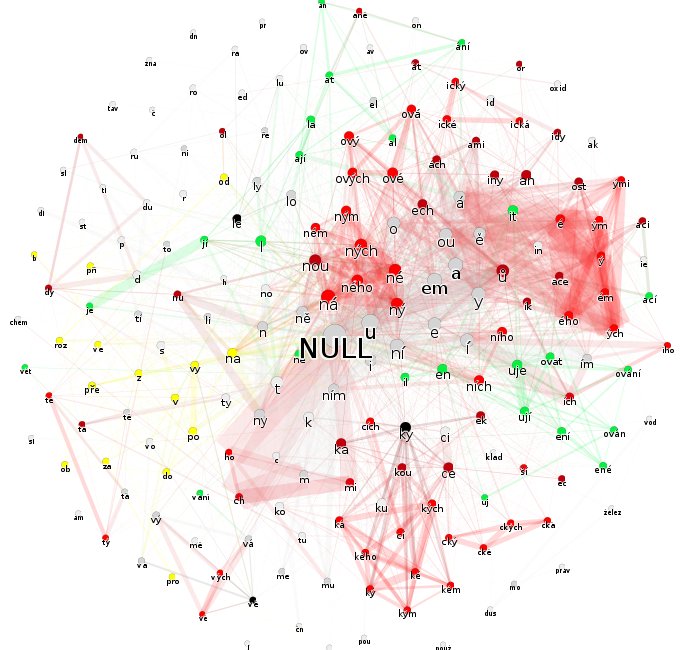
Zvláště grafy, v nichž jsou odfiltrovány hrany nízkých vah, jasně ukazují typologický rozdíl mezi češtinou a angličtinou. Dobrat se podobnému závěru pouze z prostého textu je pro člověka téměř nemožné. Aby člověk mohl klasifikovat jazyk textu, musel by ovládnout příslušný jazyk nebo alespoň pochopit základy jeho gramatiky čili předvedené zpracování textu vykazuje známky silné umělé inteligence. I rozložení grafů nese neklamné známky umělé inteligence. Například v posledním grafu jsou všechny předpony (žluté uzly) seskupeny výhradně nalevo.
Pozorování týkající se Babičky:
- Mnohé podřetězce nabíledni souvisejí s časováním, s vidovými změnami a zájmem o opakovanost u akcí (např. áv, běhá versus běhává). Text dobře dokládá problematiku českého slovesa, a bude zřejmě popisovat nějaké zápletky.
- Text nedostatečně dokládá problematiku posesivních adjektiv (otcův, matčin). Omezený počet dokladů nasvědčuje omezenému počtu jednajících osob.
- Převládající tvary příčestí (např. aly) a přechodníků nasvědčují, že podměty vět jsou gramaticky převážně ženského rodu.
- Přechodníky současné (např. jíc) naznačují, že se nejedná o soudobý text. Jednak jsou přechodníky pociťovány jako archaizující prvek, jednak moderní literatura tíhne spíše k rychlému dějovému spádu, zřídka popisujíc doprovodné děje.
Pozorování týkající se chemického textu:
- Hojně, až na přivlastňovací adjektiva, je doložené české přídavné jméno. To nasvědčuje, že text obsahuje mnoho sousloví (např. kyselina sýrová).
- Rovněž zvolené texty nedostatečně ilustrují problematiku českého slovesa. Chybí doklady první a druhé osoby, rozkazovacího způsobu a podobně. To nasvědčuje, že text je napsán v er-formě. Častý bude pravděpodobně výskyt slovesa být.
- Potlačeny jsou předpony, jimiž se mění vid, a zcela chybějí příčestí minulá. Zřetel textu tedy není kladen ani na časové zařazení děje, ani na vidové protiklady. Slovesa budou pravděpodobně v gnómickém prézentu, tedy věty budou pojednávat o časově nezařazených obecně platných skutečnostech.
Výše uvedená pozorování naznačují u prvního českého vzorku, že spadá pod beletrii, a u druhého českého vzorku, že se jedná o odborný výklad. Jen ze znalosti české gramatiky a rozborem grafů se podařilo žánrově správně zařadit ukázkové texty.













