 Nabíhající KNIME
Nabíhající KNIME
Klikací pracovní plocha
Stejně jako u tabulkových procesorů, je tabulka základní datovou strukturou i u KNIME. Oproti tabulkovým procesorům je zde ale nad editorem tabulek ještě další vrstva: „procesní datový tok“. Uživatel si nakliká uzly, kterými jsou reprezentovány různé druhy algoritmů, a šipkami určí, jak se mezi uzly data distribuují. Pro přehlednost si lze schéma popsat a třeba i související uzly sloučit do naduzlu (metanode).
 Naklikané schéma
Naklikané schéma
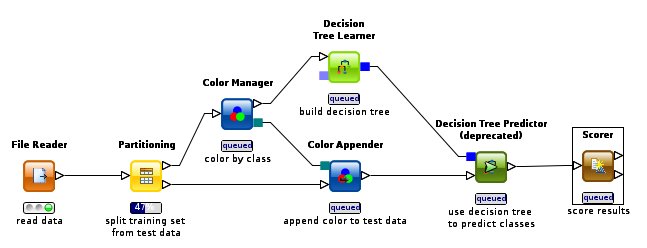
Schéma uvedené na obrázku definuje postup, kdy se data lineárně zpracovávají v patnácti sekvenčních krocích. Každému kroku odpovídá jeden uzel, jehož druh značí různé ikony. Základní instalace KNIME obsahuje jen několik desítek uzlů, ačkoliv celkově je v repozitářích uzlů přes tisíc. Nedostupnost algoritmu indikuje kostkovaná ikona s červeným křížkem.
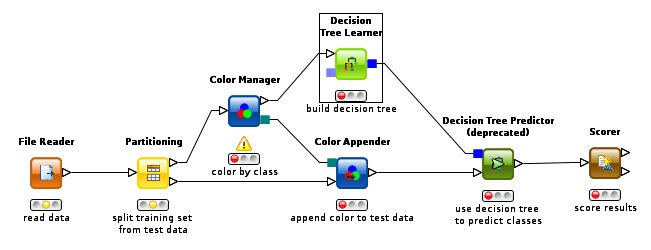 Větvené schéma
Větvené schéma
Schématem v KNIME může být jakýkoliv acyklický graf. Vstupním uzlem může být databázový konektor, čtečka CSV souborů, importér datových souborů ve formátech podporovaných aplikací (tabulkové procesory, Weka...), editor tabulek nebo generátor náhodných dat, specializované uzly též interpretují materiály zcela nečíselné povahy (texty, mapy, obrázky...).
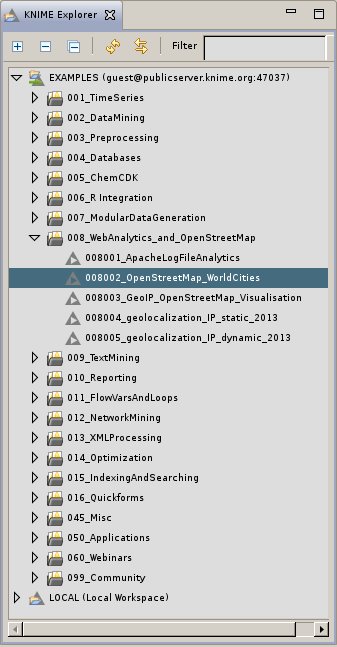 Obsah veřejné databáze příkladů
Obsah veřejné databáze příkladů
Uzly, které vizualizují data, navíc mohou otevírat okna s vygenerovanou grafikou. Terminální (koncové) uzly vizualizují výstupy, ukládají je do souborů, zapisují do databází, zasílají výstupy v přílohách mailů či jinak výsledky zpracování exportují.
 Průzkumník, možnost přihlášení se do databáze příkladů
Průzkumník, možnost přihlášení se do databáze příkladů
Z doprovodných ukázek ve veřejné online databázi, která je přístupná zdarma bez omezení, si lze snadno udělat obrázek o různorodosti možných nasazení KNIME. Například tam nalezneme aplikaci, jež na základě geografických dat z OpenStreetMap kalkuluje riziko lesního požáru. Rovněž schéma na výše uvedeném obrázku („Naklikané schéma“), jímž se analyzují texty z deníku The New York Times, má původ v této databázi.
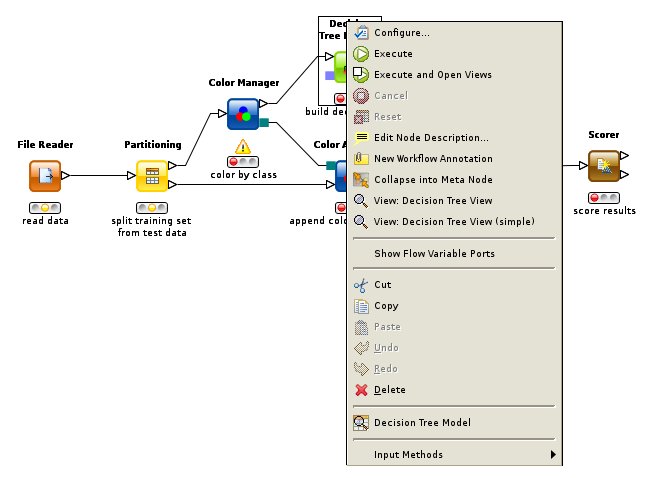 Nabídka uzlu obsahuje také spouštěč uzlu (Execute)
Nabídka uzlu obsahuje také spouštěč uzlu (Execute)
Pod uzly svítí semafor. Červená značí, že není řádně nakonfigurován tento uzel nebo uzly jemu předcházející. Konfigurace uzlu spočívá v určení zpracovávaných sloupců, určení souborové cesty u čtečky souborů, určení parametrů algoritmu, definování algoritmu napsáním vlastního skriptu v Javě nebo v jazyce R, nastavení grafu a podobně, plus samozřejmě i v nakonfigurování všech předcházejících uzlů.
U uzlů lze nastavovat i management paměti, aby si KNIME právě nezpracovávaná data samočinně odkládalo na disk. (Konkurenční produkty obvykle drží všechna data v operační paměti, uvolňování paměti swapováním nechávají na operačním systému.) Žlutá na semaforu informuje, že uzel nebyl spuštěn. Zelená je vyhrazena stavu, kdy zpracování dat je zcela dokončené.
 Právě řešená úloha
Právě řešená úloha
Vytvořené schéma lze též provést v terminálu dávkově, aniž se spustí grafické prostředí.
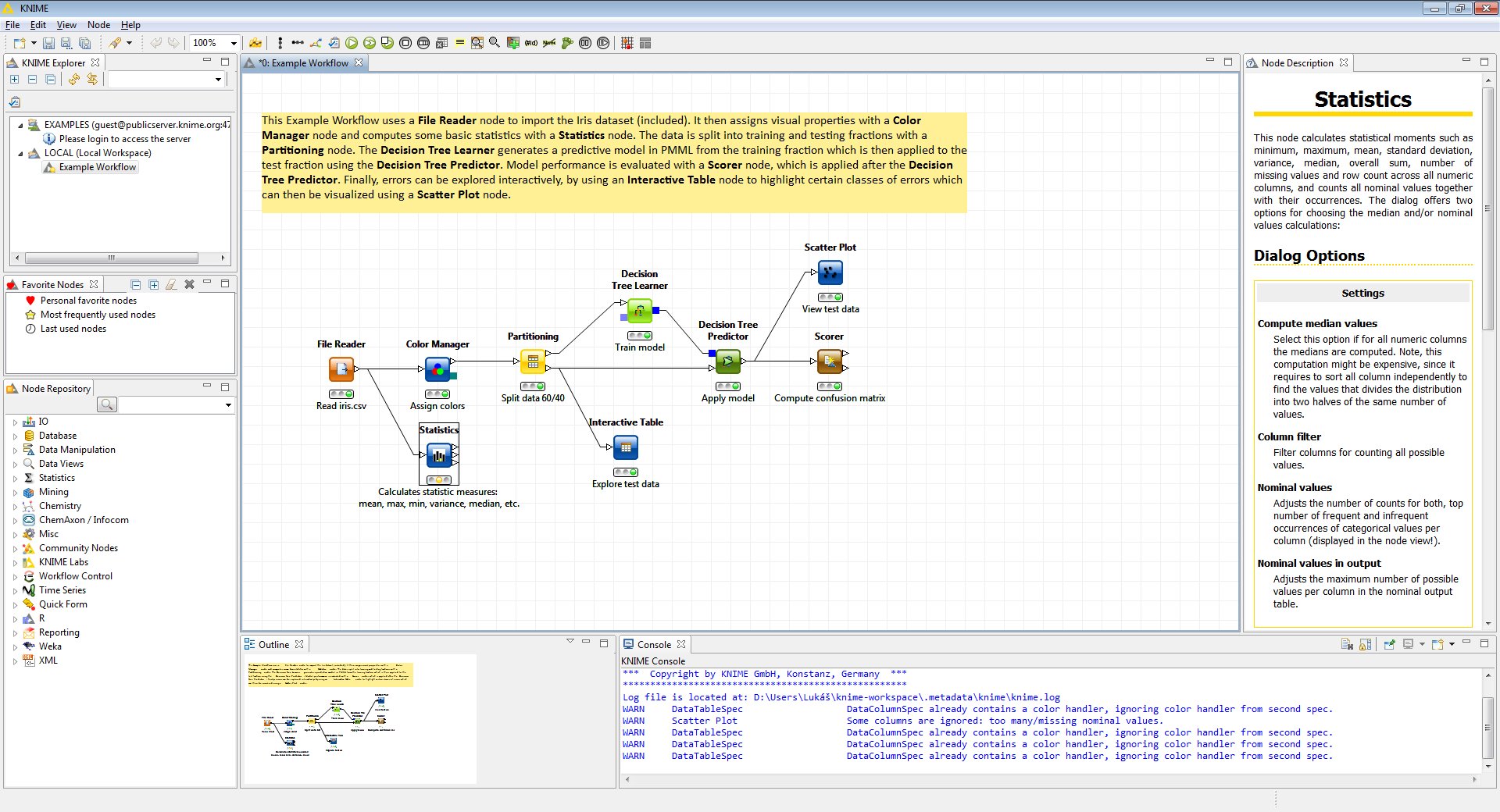
Co obsahuje projekt KNIME?
Aplikace KNIME a vývojářská verze KNIME SDK jsou nadstavbou populárního javovského vývojového prostředí Eclipse. Pro dobře rozšiřovatelné Eclipse existují desítky nejrůznějších rozšíření (např. Aptana pro vývoj interaktivních webů). KNIME je běžným pluginem: respektuje standardní aplikační rozhraní Eclipse, nemění mechanismus upgradování, využívá systém pohledů/perspektiv a zachovává klasický vzhled prostředí Eclipse.
 Vzhled KNIME
Vzhled KNIME
Standardní instalaci KNIME lze dále rozšiřovat mnoha doplňky, ať již určených obecně pro Eclipse nebo vyvinutých přímo pro KNIME. Některá rozšíření jsou však zpoplatněna.
 Nabídka doplňků
Nabídka doplňků
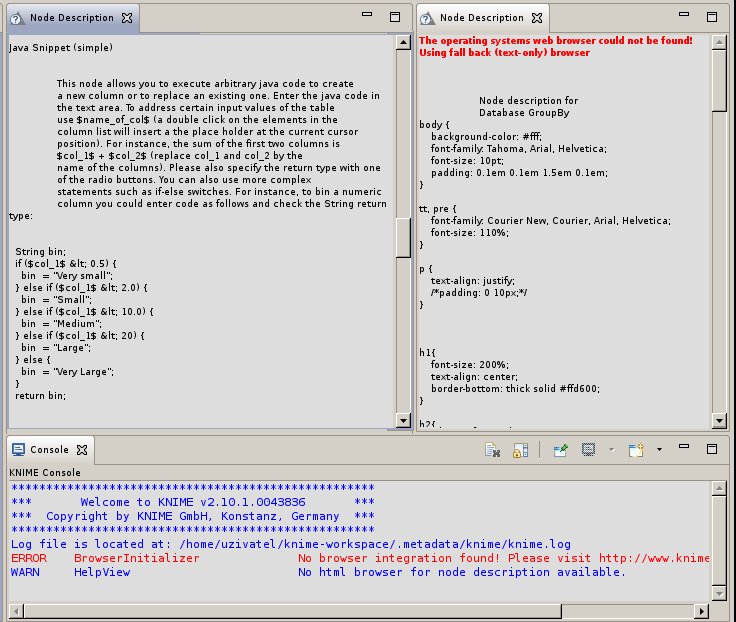
Chybějící podrobnou nápovědu supluje databáze příkladů, dvacet megabytů různých dat vhodných k statistickému zpracování, krátká informační brožura a kuchařka komentovaných příkladů The KNIME Cookbook: Recipes for the Advanced User – název zjevně odkazuje na řadu publikací Numerické recepty za přibližně 400 Kč – a hlavně nápověda jednotlivých uzlů. Pro správné zobrazení popisků k uzlům je však třeba spolupráce komponent operačního systému pro vykreslovaní HTML stránek.
 Nenaformátované vzorce, výpis stylu a chybové hlášení
Nenaformátované vzorce, výpis stylu a chybové hlášení
Bez funkčního napojení na knihovny webového prohlížeče se neinterpretují styly a formátování textu, popisek se pak vypíše jako neformátovaný text. Tento triviální problém postihuje většinu linuxových distribucí, ale snadno se odstraní. V prostředí linuxových distribucí, kde bývá předpřipravena platforma Java SE, nevyžaduje KNIME žádnou jinou konfiguraci ani instalaci podpůrného softwaru.
Důležitá je podpora skriptování v R, což je jednak jazyk pro popis manipulací se statistickými daty, jednak jde i o komplexní statistické prostředí obsahující interpret jazyka R s různou doprovodnou funkcionalitou jako vykreslování grafů. Jazyk R je odvozen od staršího jazyka S. Oproti proprietárnímu S je standardní implementace jazyka R open source.
Kolem svobodného R se rychle vytvořila široká obec uživatelů, která velmi rychle do projektu přidávala různá rozšíření. Projekt R rozsahem svých funkcí, tržním podílem, součinností s jinými projekty, kvalitou dokumentace i celkovou popularitou zcela zastínil S, stal se výrazně dominantním řešením pro pokročilou statistiku, a tak téměř každý, kdo se intenzivněji zabýval statistikou, se s prostředím R již setkal.
Dále KNIME podporuje všechny moduly aplikace Weka a souborový formát Weky (přípona ARFF). Weka, kterou vyvíjí novozélandská univerzita, je rozsáhlý soubor algoritmů v oboru datamingu a strojového učení. Ve svém oboru patří Weka jednoznačně k nejuznávanějším produktům. Weku využívá mimo jiné i businessový open source balík Pentaho. Pro oblast chemie a farmakologie disponuje KNIME doplňkem Chemistry kit a podporou editoru chemických vzorců Marvin.
Co je to data mining?
Česká Wikipedie praví: „Data mining ([dejta majnyn], angl. dolování z dat či vytěžování dat) je analytická metodologie získávání netriviálních skrytých a potenciálně užitečných informací z dat. Někdy se chápe jako analytická součást dobývání znalostí z databází (Knowledge Discovery in Databases, KDD), jindy se tato dvě označení chápou jako souznačná. Data mining se používá v komerční sféře (například v marketingu při rozhodování, které klienty oslovit dopisem s nabídkou produktu), ve vědeckém výzkumu (například při analýze genetické informace) i v jiných oblastech (například při monitorování aktivit na internetu).“
V oboru data mining je například typické, že:
- Klíčové jsou možnosti exportu dat z databází, interoperabilita se specializovaným softwarem a snadnost úprav formátu dat jako filtrace řádků tabulky, filtrace atributů, vzorkování, převod fyzikálních jednotek, práce s datumy, diskretizace hodnot či spojování tabulek.
- Pro adekvátní popis systému je nezbytná strojová analýza využívající nejrůznějších statistických metod.
- Nalezení vhodného postupu zpracování dat je do značné míry věcí intuice a zkoušení.
- Při řešení je výhodné výsledky vizualizovat formou grafů. Grafy usnadňují interpretaci výstupů.
- Jsou známy pouze vnější projevy (např. chování návštěvníků webu). Na příčiny a důvody (např. záměry návštěvníků) lze jen usuzovat.
- Ač je dat velké množství, nejsou data úplná a bezchybná. Je potřeba identifikovat a vyřadit nereprezentativní a zavádějící údaje.
- Strojové zpracování poskytuje libovolně velké množství poznatků. Je potřeba vytřídit nejdůležitější poznatky a kvantifikovat věrohodnost závěrů.
Praktickou ukázku data miningu předvedl vlastně i minulý článek Gephi z hromady dat přehledný grafický výstup: pracovní postup o nástroji Gephi. KNIME však z výstupu skriptu, jenž je přílohou zmíněného článku, dokáže vytěžit daleko niternější poznatky (např. metodou koncovky jednotlivých vzorů) než jednoduchý vizualizační nástroj Gephi.
Uzly dostupné v základní instalaci KNIME
 Nabídky s uzly (fotomontáž)
Nabídky s uzly (fotomontáž)
Nezbytností jsou uzly pro vstup a výstup (kategorie IO, Input/Output), pro problematiku databází (kategorie Database) a uzly pro různé pomocné úkony (kategorie Data Manipulation). Nezřídka je nutné vypořádat se se selháním databáze, mnohdy se musí volit mezi více způsoby zpracování podle velikosti zpracovávaného statistického souboru, zkrátka často je třeba přizpůsobit se nastalým okolnostem.
Podobné nepříjemnosti řeší uzly z kategorie řízení toku (Flow Control). Někdy je nutné zohledňovat informace o denní době, o jevech vyvolaných sezonními změnami (např. zimní počasí), o různých lhůtách, o zúčtovacích obdobích, o dni v týdnu... Zde pomohou uzly z kategorie časových řad (kategorie Time Series). V kategorie různé (kategorie Misc) se mimo jiné ukrývají uzly pro skriptování v Javě, jimiž si uživatel definuje vlastní logiku zpracování dat.
 Vizualizační uzly
Vizualizační uzly
Uzly pro vizualizaci vykreslí všechny základní typy dvojrozměrných grafů. Přímo v KNIME je integrována javovská knihovna JFreeChart, která toto obstarává. Recenzi knihovny JFreeChart naleznete v článku Knihovna JFreeChart vyrobí z nudných čísel hezké grafy.
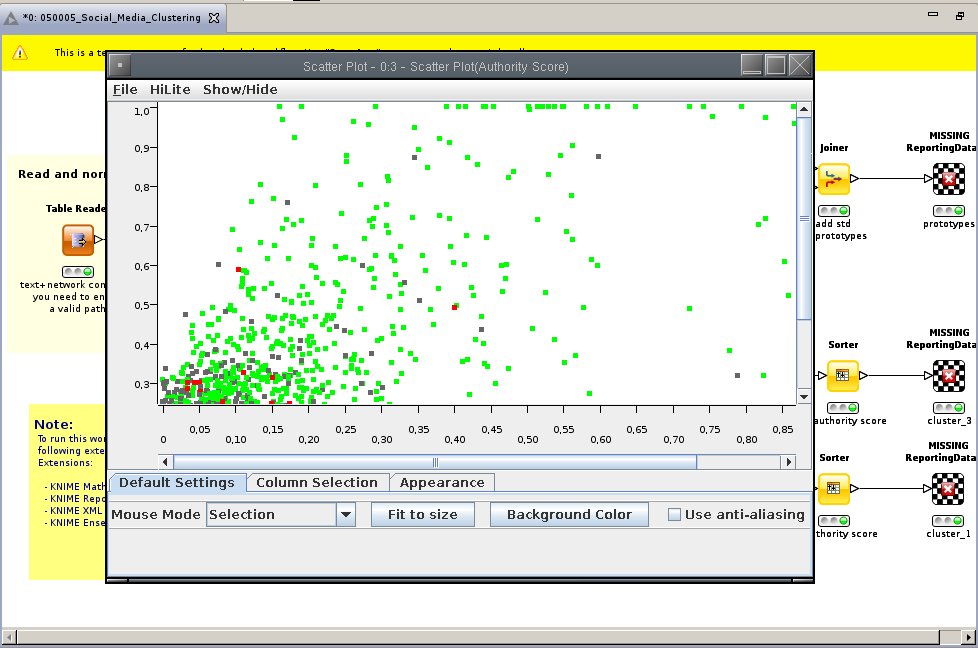 Ukázka bodového grafu
Ukázka bodového grafu
Meritem dataminingové aplikace KNIME jsou kategorie statistika (Statistics) a data mining (Mining).
Komentáře k některým podkategoriím:
- Testování hypotéz provádí analýzy rozptylu (ANOVA).
- U regresí se jedná o aproximování číselných dat předpokládanou teoretickou závislostí (např. přímkou).
- Bayesovská pravděpodobnost stanovuje četnost jevů a následně určí pravděpodobnosti.
- Algoritmy pro clustering sdružují prvky do množin (clusterů). Rozdělení do clusterů se optimalizuje tak, aby prvky jednoho clusteru se sobě podobaly a aby prvky různých clusterů se lišily a aby počet clusterů byl minimální.
- Neuronové sítě jsou různé algoritmy, které jsou inspirované poznatky biologie o nervové tkáni.
- Asociativní pravidla jsou výroky ve tvaru Hornových klauzulí, tedy výroky následujícího typu. Pokud si zákazník koupí produkty A, B, C, D, pak si koupí i produkt E. Jestliže bankéř často provádí nestandardní transakce, dlouhodobě odmítá nastoupit dovolenou a nechce se dělit o pracovní úkoly, žije si zjevně nad poměry a v minulosti byl soudně trestaný, pak se dopouští zpronevěry. Algoritmy typu Association rule learning hledají v empirických datech tato pravidla.
- Algoritmy generující rozhodovací stromy de facto uspořádávají asociativní pravidla do stromové struktury. Při průchodu stromem se kladou dotazy. Když se získá dostatek odpovědí, jež tvoří premisu některého z asociativních pravidel, lze učinit závěr.
- MDS (Multidimensional scaling) usiluje o nalezení projekce metrického prostoru do metrického prostoru o nižší dimenze takové, že projekce maximálně respektuje vzdálenosti mezi zadanými body.
- SVM (Support vector machine) řeší problém, jak nejlépe oddělit dvě množiny prvků hraniční plochou. SVM hledá hranici ve tvaru roviny.
- PCA (Principal component analyse) se využívá hlavně v elektrotechnice, když se odděluje signál od šumu. Matematicky se jedná o problém nalezení ortogonální transformace, která totálně dekoreluje vstupní data.
 Uzly pro statistiku a data mining
Uzly pro statistiku a data mining
Závěr
Statistické prostředí KNIME je vyspělá odladěná aplikace s aktivní vývojářskou komunitou. Zajímavě je řešeno uživatelské rozhraní, které výrazně zpřehledňuje práci. Podobným grafickým rozhraním disponuje alternativa Orange. Ač je Orange většinou uživatelů poměrně kladně hodnoceno, sám mám s Orange špatné zkušenosti (časté pády aplikace, vznik konfliktů při upgradu, různé neočekávané chování, chabá technická dokumentace), proto jednoznačně doporučuji KNIME.
Aplikace KNIME vzniká při univerzitě v německé Kostnici (Universität Konstanz) a jednoznačně spadá do kategorie komerčního open source. Obchodní model je založen na licenci GPLv3. Na aplikační rozhraní se nevztahují licenční omezení, a tak lze ke KNIME připojovat placené moduly a moduly jinak neslučitelné s principy GNU GPL.
Za komerční služby si poskytovatel společnost KNIME GmbH účtuje řádově desítky až stovky tisíc korun, což lze hodnotit jako cenu obvyklou u profesionálního matematického a podnikového softwaru. Konkrétně za základní servis Personal Productivity KNIME se platí 300 eur, u programu TeamSpace KNIME za každého uživatele 2 000 eur, u Partner Productivity KNIME je to 5 000 eur na uživatele, u Server Lite KNIME pro více než pět uživatelů 7 500 eur a u WebPortal Lite KNIME pro více než pět uživatelů 12 500 eur.
Nejrozsáhlejší služba KNIME Server není naceněná; zřejmě cena služby závisí na konkrétních požadavcích a na individuální dohodě s obchodníkem. Placenou podporu odebírají (asi) především velké organizace, které potřebují analyzovat rozsáhlé množiny podnikových, průmyslových nebo vědeckých dat uložené v cloudech. Pro zpracování velkých dat se dodává rozšíření Big data extension podporující distribuovaný systém Hadoop/HDFS.
Aplikace se zaměřuje především na profesionály, kteří analyzují rozsáhlá data. Předpokládají se znalosti v oboru statistiky v rozsahu výrazně překračujícím požadavky maturity z matematiky, a to včetně odborné anglické terminologie, přehled o principech podnikového softwaru (např. SQL databáze), povědomí o Javě a o systému R, znalost angličtiny apod. V běžných případech statistického zpracování firemních dat malých a středních podniků je výhodnější zvolit tabulkové procesory, které nekladou takové nároky na kvalifikaci své obsluhy a funkčností plně dostačují.












